Redis 캐싱 전략과 내부 아키텍처
Redis가 빠른 이유
이 글은 Redis 7.x, Spring Boot 3.2+ 기준으로 작성되었습니다.
"캐시 쓰면 빨라진다"는 건 다들 아는데, Redis가 왜 빠른지는 의외로 잘 모르는 경우가 많습니다. 단순히 "메모리니까 빠르다"로 끝나는 게 아니에요.
In-Memory 저장
가장 기본적인 이유입니다. 디스크 I/O 없이 메모리에서 직접 읽고 쓰니까 빠릅니다. SSD도 마이크로초 단위인데, 메모리는 나노초 단위거든요.
디스크 (HDD): ~10ms
디스크 (SSD): ~0.1ms
메모리 (RAM): ~0.0001ms (100ns)
약 1000배 차이가 납니다.
Single Thread + I/O Multiplexing
Redis는 싱글 스레드입니다. "어? 멀티 스레드가 더 빠른 거 아니야?"라고 생각할 수 있는데, 상황에 따라 다릅니다.
멀티 스레드는 컨텍스트 스위칭 비용과 락 경쟁이 발생합니다. Redis는 대부분의 연산이 메모리에서 O(1) 또는 O(log N)으로 끝나기 때문에, 락 오버헤드 없이 싱글 스레드로 처리하는 게 오히려 효율적입니다.
대신 여러 클라이언트 연결은 I/O Multiplexing(epoll, kqueue)으로 처리합니다. 하나의 스레드가 수만 개의 연결을 동시에 관리할 수 있어요.
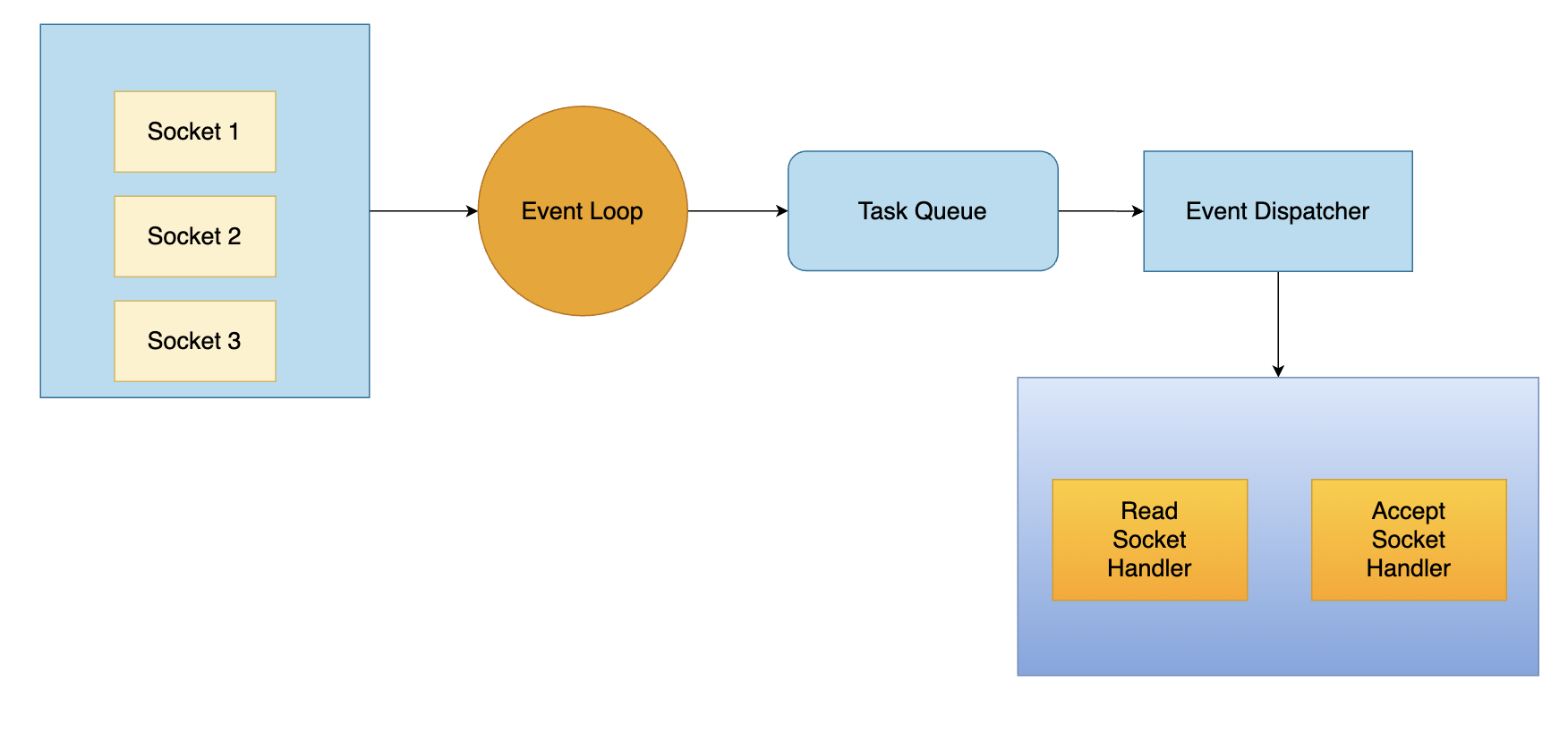 Redis Single Thread Event Loop - I/O Multiplexing으로 수천 개의 연결을 동시 처리
Redis Single Thread Event Loop - I/O Multiplexing으로 수천 개의 연결을 동시 처리
효율적인 자료구조
Redis는 단순 Key-Value가 아닙니다. 내부적으로 상황에 따라 다른 인코딩을 사용해요.
예를 들어 Hash 타입은:
- 필드가 적고 값이 작으면 →
listpack(메모리 효율적) - 필드가 많아지면 →
hashtable(속도 효율적)
# Hash 필드가 적을 때
> HSET user:1 name "Kim" age "30"
> DEBUG OBJECT user:1
encoding:listpack # 메모리 효율적인 인코딩
# Hash 필드가 많아지면 자동 전환 (기본 512개 초과 시)
> HSET user:1 field1 val1 field2 val2 ... (512개 이상)
encoding:hashtable # 속도 효율적인 인코딩
참고로 Redis 7.0 이전에는 ziplist였는데 listpack으로 대체되었습니다. 전환 기준은 hash-max-listpack-entries(기본 512)와 hash-max-listpack-value(기본 64바이트)로 설정할 수 있어요.
이런 자동 최적화 덕분에 개발자가 신경 쓰지 않아도 됩니다.
Redis 데이터 구조
Redis를 그냥 Key-Value 저장소로만 쓰면 손해입니다. 다양한 자료구조를 활용하면 네트워크 왕복을 줄일 수 있어요.
| 타입 | 용도 | 주요 명령어 |
|---|---|---|
| String | 단순 값, 카운터, 세션 | GET, SET, INCR, DECR |
| Hash | 객체 저장 | HGET, HSET, HGETALL |
| List | 큐, 최근 항목 | LPUSH, RPOP, LRANGE |
| Set | 태그, 고유 항목 | SADD, SMEMBERS, SINTER |
| Sorted Set | 랭킹, 점수 기반 정렬 | ZADD, ZRANGE, ZRANK |
| HyperLogLog | 대용량 카디널리티 추정 | PFADD, PFCOUNT |
실전 예시: 랭킹 시스템
DB로 랭킹을 구현하면 매번 정렬 쿼리가 필요합니다. Redis Sorted Set을 쓰면 O(log N)에 끝나요.
// 점수 업데이트
redisTemplate.opsForZSet().add("game:ranking", "player1", 1500);
redisTemplate.opsForZSet().add("game:ranking", "player2", 1800);
redisTemplate.opsForZSet().add("game:ranking", "player3", 1200);
// 상위 10명 조회 (높은 점수순)
Set<String> top10 = redisTemplate.opsForZSet()
.reverseRange("game:ranking", 0, 9);
// 특정 유저 순위 조회
Long rank = redisTemplate.opsForZSet()
.reverseRank("game:ranking", "player1");
캐싱 전략
캐싱 전략은 크게 4가지가 있습니다. 상황에 따라 적절한 전략을 선택해야 해요.
1. Cache-Aside (Lazy Loading)
가장 많이 쓰는 패턴입니다. 애플리케이션이 캐시를 직접 관리해요.
읽기:
1. 캐시 조회
2. 캐시에 있으면 → 반환 (Cache Hit)
3. 캐시에 없으면 → DB 조회 → 캐시 저장 → 반환 (Cache Miss)
쓰기:
1. DB 업데이트
2. 캐시 삭제 (또는 업데이트)
public User getUser(Long id) {
String key = "user:" + id;
// 1. 캐시 조회
User cached = (User) redisTemplate.opsForValue().get(key);
if (cached != null) {
return cached; // Cache Hit
}
// 2. DB 조회
User user = userRepository.findById(id)
.orElseThrow(() -> new UserNotFoundException(id));
// 3. 캐시 저장 (TTL 1시간)
redisTemplate.opsForValue().set(key, user, Duration.ofHours(1));
return user;
}
public void updateUser(Long id, UserUpdateRequest request) {
// 1. DB 업데이트
userRepository.update(id, request);
// 2. 캐시 삭제 (다음 조회 시 새로 캐싱)
redisTemplate.delete("user:" + id);
}
장점: 필요한 데이터만 캐싱, 구현 간단 단점: 첫 요청은 항상 느림 (Cold Start), 캐시와 DB 불일치 가능
2. Write-Through
쓰기 시 캐시와 DB를 동시에 업데이트합니다.
쓰기:
1. 캐시 업데이트
2. DB 업데이트 (동기)
읽기:
1. 캐시 조회 (항상 Hit)
public void updateUser(Long id, UserUpdateRequest request) {
User user = // ... 업데이트된 User 객체 생성
// 캐시와 DB 동시 업데이트
redisTemplate.opsForValue().set("user:" + id, user);
userRepository.save(user);
}
장점: 캐시와 DB 일관성 보장 단점: 쓰기 레이턴시 증가, 읽히지 않을 데이터도 캐싱
3. Write-Behind (Write-Back)
쓰기를 캐시에만 하고, DB 반영은 나중에 비동기로 합니다.
쓰기:
1. 캐시 업데이트
2. 변경 내역 큐에 저장
3. 백그라운드에서 DB 반영
읽기:
1. 캐시 조회
장점: 쓰기 성능 극대화, DB 부하 분산 단점: 데이터 유실 위험, 구현 복잡
실시간성이 덜 중요한 로그나 통계에 적합합니다.
4. Read-Through
Cache-Aside와 비슷하지만, 캐시 라이브러리가 DB 조회를 대신합니다.
// Spring Cache 추상화 사용
@Cacheable(value = "users", key = "#id")
public User getUser(Long id) {
return userRepository.findById(id)
.orElseThrow(() -> new UserNotFoundException(id));
}
Spring의 @Cacheable이 대표적인 Read-Through 방식입니다.
전략 비교
| 전략 | 읽기 성능 | 쓰기 성능 | 일관성 | 복잡도 |
|---|---|---|---|---|
| Cache-Aside | 좋음 (Hit 시) | 보통 | 낮음 | 낮음 |
| Write-Through | 좋음 | 낮음 | 높음 | 보통 |
| Write-Behind | 좋음 | 높음 | 낮음 | 높음 |
| Read-Through | 좋음 (Hit 시) | 보통 | 낮음 | 낮음 |
대부분의 경우 Cache-Aside로 충분하고, 조회가 압도적으로 많으면 Read-Through(Spring Cache)가 편합니다.
TTL과 만료 정책
TTL 설정
모든 캐시에는 TTL(Time To Live)을 설정하는 게 좋습니다. 안 그러면 메모리가 계속 쌓여요.
// 기본 TTL 설정
redisTemplate.opsForValue().set("key", value, Duration.ofMinutes(30));
// Spring Cache에서 TTL 설정
@Bean
public RedisCacheConfiguration cacheConfiguration() {
return RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofHours(1))
.disableCachingNullValues();
}
적절한 TTL 값은 어떻게 정할까요? 정답은 없지만 가이드라인은 있습니다.
| 데이터 유형 | 권장 TTL | 이유 |
|---|---|---|
| 세션 | 30분~2시간 | 보안, 사용자 비활동 시간 기준 |
| 사용자 프로필 | 1~24시간 | 자주 안 바뀜 |
| 상품 목록 | 5~30분 | 재고, 가격 변동 가능 |
| 검색 결과 | 1~5분 | 실시간성 중요 |
| 설정값 | 1~6시간 | 거의 안 바뀜 |
핵심은 "데이터가 얼마나 자주 바뀌는가" + "오래된 데이터를 보여줘도 괜찮은가"입니다.
Redis의 만료 처리 방식
Redis는 두 가지 방식으로 만료된 키를 삭제합니다.
- Passive Expiration: 키에 접근할 때 만료 여부 확인 후 삭제
- Active Expiration: 백그라운드에서 주기적으로 샘플링하여 삭제
Active Expiration은 초당 10회씩 실행되며, 랜덤하게 20개의 키를 샘플링해서 만료된 것을 삭제합니다. 25% 이상이 만료되었으면 다시 반복해요. 그래서 만료된 키가 즉시 삭제되지 않을 수 있습니다.
Eviction Policy
메모리가 가득 차면 어떤 키를 삭제할지 정하는 정책입니다.
| 정책 | 설명 |
|---|---|
| noeviction | 삭제 안 함, 쓰기 오류 발생 |
| allkeys-lru | 모든 키 중 LRU (가장 오래 안 쓴 키) 삭제 |
| volatile-lru | TTL 있는 키 중 LRU 삭제 |
| allkeys-random | 모든 키 중 랜덤 삭제 |
| volatile-ttl | TTL 짧은 키부터 삭제 |
| allkeys-lfu | 모든 키 중 LFU (가장 덜 쓴 키) 삭제 (Redis 4.0+) |
# redis.conf
maxmemory 2gb
maxmemory-policy allkeys-lru
캐시 용도라면 allkeys-lru가 무난합니다.
Spring Boot + Redis 연동
의존성 추가
// build.gradle
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
implementation 'org.springframework.boot:spring-boot-starter-cache'
}
설정
# application.yml
spring:
data:
redis:
host: localhost
port: 6379
password: ${REDIS_PASSWORD:}
timeout: 3000ms
lettuce:
pool:
max-active: 8
max-idle: 8
min-idle: 2
Redis 설정 클래스
@Configuration
@EnableCaching
public class RedisConfig {
@Bean
public RedisConnectionFactory redisConnectionFactory(
RedisProperties properties) {
RedisStandaloneConfiguration config =
new RedisStandaloneConfiguration();
config.setHostName(properties.getHost());
config.setPort(properties.getPort());
if (properties.getPassword() != null) {
config.setPassword(properties.getPassword());
}
LettuceClientConfiguration clientConfig =
LettuceClientConfiguration.builder()
.commandTimeout(properties.getTimeout())
.build();
return new LettuceConnectionFactory(config, clientConfig);
}
@Bean
public RedisTemplate<String, Object> redisTemplate(
RedisConnectionFactory connectionFactory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(connectionFactory);
// 직렬화 설정
template.setKeySerializer(new StringRedisSerializer());
template.setValueSerializer(new GenericJackson2JsonRedisSerializer());
template.setHashKeySerializer(new StringRedisSerializer());
template.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());
return template;
}
@Bean
public CacheManager cacheManager(RedisConnectionFactory connectionFactory) {
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofHours(1))
.serializeKeysWith(
RedisSerializationContext.SerializationPair
.fromSerializer(new StringRedisSerializer()))
.serializeValuesWith(
RedisSerializationContext.SerializationPair
.fromSerializer(new GenericJackson2JsonRedisSerializer()))
.disableCachingNullValues();
return RedisCacheManager.builder(connectionFactory)
.cacheDefaults(config)
.withCacheConfiguration("users",
config.entryTtl(Duration.ofMinutes(30)))
.withCacheConfiguration("products",
config.entryTtl(Duration.ofHours(6)))
.build();
}
}
캐시 어노테이션 사용
@Service
public class UserService {
private final UserRepository userRepository;
// 캐시 조회 (없으면 메서드 실행 후 캐싱)
@Cacheable(value = "users", key = "#id")
public User findById(Long id) {
return userRepository.findById(id)
.orElseThrow(() -> new UserNotFoundException(id));
}
// 캐시 업데이트
@CachePut(value = "users", key = "#user.id")
public User update(User user) {
return userRepository.save(user);
}
// 캐시 삭제
@CacheEvict(value = "users", key = "#id")
public void delete(Long id) {
userRepository.deleteById(id);
}
// 전체 캐시 삭제
@CacheEvict(value = "users", allEntries = true)
public void clearCache() {
// 캐시만 삭제
}
}
캐시 무효화 전략
캐시에서 가장 어려운 문제가 무효화입니다. 언제 캐시를 지워야 할까요?
1. TTL 기반
가장 단순합니다. 일정 시간 후 자동 만료.
redisTemplate.opsForValue().set("key", value, Duration.ofMinutes(5));
적합한 경우: 약간의 지연이 괜찮은 데이터 (상품 목록, 공지사항)
2. 이벤트 기반
데이터 변경 시 명시적으로 캐시 삭제.
@TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT)
public void handleUserUpdate(UserUpdatedEvent event) {
redisTemplate.delete("user:" + event.getUserId());
redisTemplate.delete("users:list"); // 목록 캐시도 삭제
}
적합한 경우: 실시간성이 중요한 데이터
3. 패턴 기반 삭제
관련 캐시를 한 번에 삭제.
// user:* 패턴의 모든 키 삭제
Set<String> keys = redisTemplate.keys("user:*");
if (keys != null && !keys.isEmpty()) {
redisTemplate.delete(keys);
}
주의: KEYS 명령은 O(N)이라 프로덕션에서 조심해야 합니다. SCAN을 쓰는 게 안전해요.
// SCAN으로 안전하게 조회
ScanOptions options = ScanOptions.scanOptions()
.match("user:*")
.count(100)
.build();
try (Cursor<byte[]> cursor = redisTemplate.getConnectionFactory()
.getConnection().scan(options)) {
while (cursor.hasNext()) {
String key = new String(cursor.next());
redisTemplate.delete(key);
}
}
운영 고려사항
메모리 관리
Redis는 메모리 DB입니다. 메모리 관리를 잘못하면 OOM으로 죽어요.
# 메모리 사용량 확인
> INFO memory
used_memory_human:1.5G
maxmemory_human:2G
권장 사항:
maxmemory설정 필수- 전체 메모리의 70-80% 정도로 설정
maxmemory-policy설정 (캐시용은 allkeys-lru)
복제 (Replication)
읽기 분산과 가용성을 위해 Replica를 둡니다.
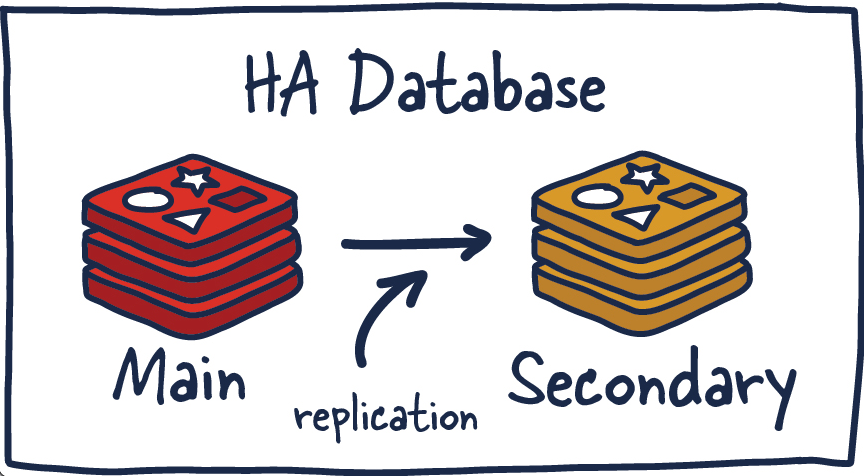 Redis Master-Replica 구조 - Master는 쓰기, Replica는 읽기 분산
Redis Master-Replica 구조 - Master는 쓰기, Replica는 읽기 분산
# replica 서버 설정
replicaof master-host 6379
Master가 죽으면 Replica 중 하나를 Master로 승격시켜야 합니다. 수동으로 하기 어려우니 Sentinel을 씁니다.
Sentinel (고가용성)
Master 장애 시 자동 Failover를 해줍니다.
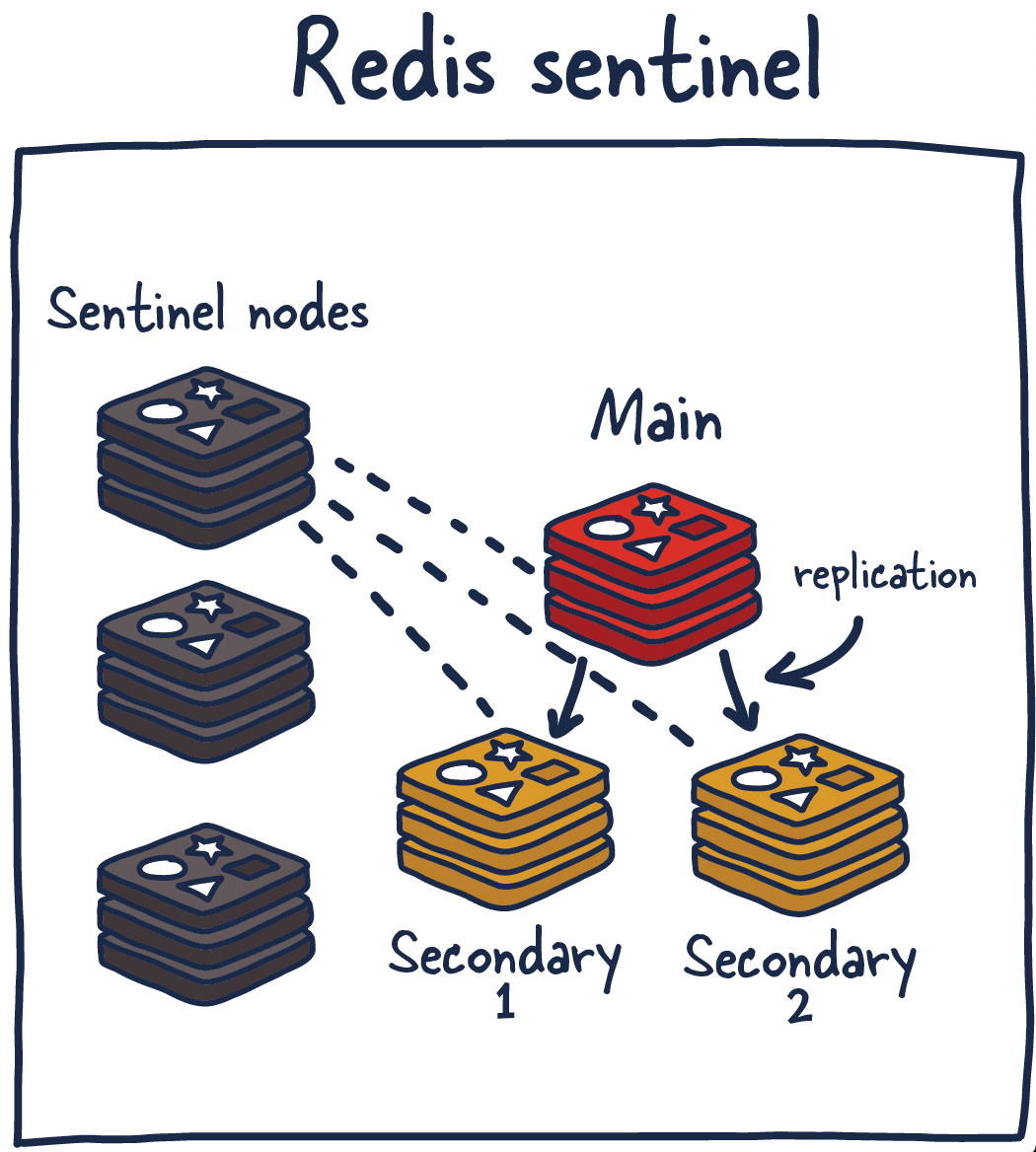 Redis Sentinel - Master 장애 시 자동 Failover 수행
Redis Sentinel - Master 장애 시 자동 Failover 수행
# Spring Boot Sentinel 설정
spring:
data:
redis:
sentinel:
master: mymaster
nodes:
- sentinel1:26379
- sentinel2:26379
- sentinel3:26379
Cluster (수평 확장)
데이터가 단일 Redis에 담기지 않을 때 사용합니다. 16384개의 슬롯으로 데이터를 분산해요.
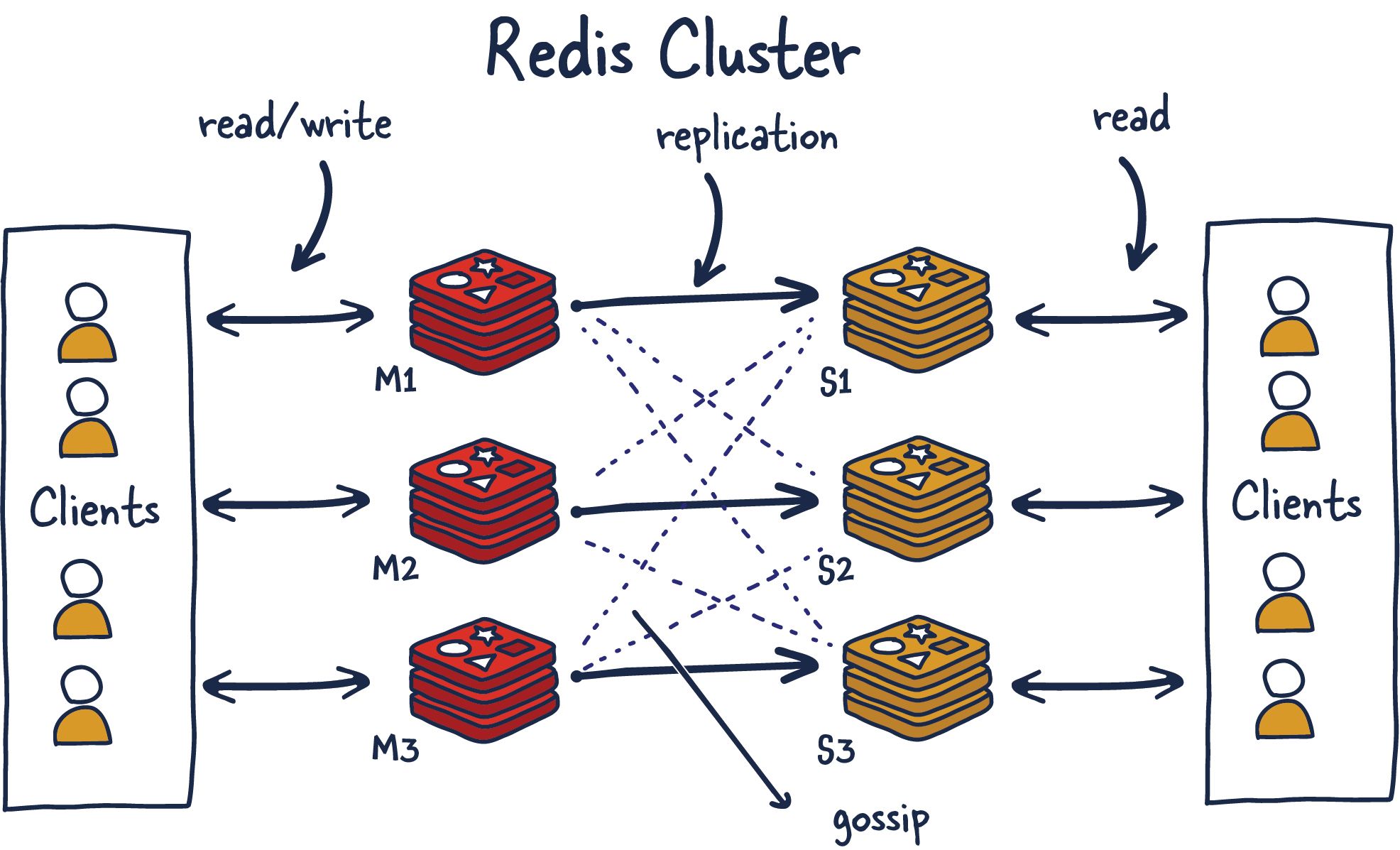 Redis Cluster - 16384개 Hash Slot을 노드에 분산하여 수평 확장
Redis Cluster - 16384개 Hash Slot을 노드에 분산하여 수평 확장
# Spring Boot Cluster 설정
spring:
data:
redis:
cluster:
nodes:
- node1:6379
- node2:6379
- node3:6379
max-redirects: 3
클러스터 모드에서는 Multi-key 연산(MGET, 트랜잭션 등)에 제약이 있습니다. 같은 슬롯에 있는 키끼리만 가능해요.
주의사항
Cache Stampede (캐시 쇄도)
인기 키의 TTL이 만료되는 순간, 동시에 수많은 요청이 DB로 몰리는 현상입니다.
시간: 10:00:00 - 캐시 만료
↓
요청 1000개 동시 발생 → DB 쿼리 1000번 → DB 죽음
해결책:
- Lock 사용: 한 요청만 DB 조회하고 나머지는 대기
public User getUser(Long id) throws InterruptedException {
String key = "user:" + id;
String lockKey = "lock:user:" + id;
User cached = (User) redisTemplate.opsForValue().get(key);
if (cached != null) return cached;
// 락 획득 시도 (SETNX + TTL)
Boolean acquired = redisTemplate.opsForValue()
.setIfAbsent(lockKey, "1", Duration.ofSeconds(10));
if (Boolean.TRUE.equals(acquired)) {
try {
// DB 조회 후 캐싱
User user = userRepository.findById(id).orElseThrow();
redisTemplate.opsForValue().set(key, user, Duration.ofHours(1));
return user;
} finally {
redisTemplate.delete(lockKey);
}
} else {
// 락 못 얻으면 잠시 대기 후 재시도
Thread.sleep(50);
return getUser(id);
}
}
실무에서는 Redisson 같은 라이브러리의 분산 락을 쓰는 게 더 안전합니다. 위 코드는 개념 이해용이에요.
- TTL 분산: 만료 시간에 랜덤값 추가
long ttl = 3600 + random.nextInt(600); // 1시간 + 0~10분
redisTemplate.opsForValue().set(key, value, Duration.ofSeconds(ttl));
Hot Key
특정 키에 요청이 집중되면 해당 Redis 노드가 병목이 됩니다.
해결책:
- 로컬 캐시와 조합 (Caffeine + Redis): 자주 접근하는 데이터를 애플리케이션 메모리에 먼저 캐싱
- 키 복제 (user:1:copy1, user:1:copy2)
- 읽기 Replica 활용
로컬 캐시 조합은 꽤 효과적입니다. Caffeine으로 1차 캐시, Redis로 2차 캐시를 구성하면 Redis 부하를 크게 줄일 수 있어요.
@Bean
public CacheManager cacheManager(RedisConnectionFactory connectionFactory) {
CaffeineCacheManager localCache = new CaffeineCacheManager();
localCache.setCaffeine(Caffeine.newBuilder()
.maximumSize(1000)
.expireAfterWrite(Duration.ofMinutes(5)));
// 로컬 캐시 Miss 시 Redis 조회하는 구조로 구성
// 또는 spring-boot-starter-cache의 CompositeCacheManager 활용
return localCache;
}
직렬화 주의
JdkSerializationRedisSerializer는 쓰지 마세요. 클래스 변경 시 역직렬화가 깨집니다.
// 나쁜 예
template.setValueSerializer(new JdkSerializationRedisSerializer());
// 좋은 예
template.setValueSerializer(new GenericJackson2JsonRedisSerializer());
JSON 직렬화를 권장합니다. 가독성도 좋고 호환성도 좋아요.
Redis vs Memcached
"왜 Memcached 대신 Redis를 쓰나요?"라는 질문을 가끔 받습니다.
| 비교 항목 | Redis | Memcached |
|---|---|---|
| 자료구조 | 다양함 (String, Hash, List, Set, Sorted Set...) | String만 |
| 영속성 | RDB/AOF로 디스크 저장 가능 | 없음 |
| 복제 | 지원 (Master-Replica) | 없음 |
| 클러스터 | 지원 | 없음 (클라이언트에서 샤딩) |
| Pub/Sub | 지원 | 없음 |
| 스레드 모델 | 싱글 스레드 | 멀티 스레드 |
| 메모리 효율 | 보통 | 약간 더 좋음 |
Memcached가 유리한 경우는 "단순 Key-Value 캐싱만 필요하고, 멀티 스레드가 필요한 경우"입니다. 하지만 대부분의 경우 Redis가 더 유연하고 기능이 풍부해서 Redis를 선택합니다.
정리
Redis가 빠른 이유:
- In-Memory 저장소 (디스크 대비 1000배 빠름)
- Single Thread + I/O Multiplexing (락 오버헤드 없음)
- 상황에 맞는 내부 자료구조 자동 최적화
캐싱 전략:
- Cache-Aside: 가장 범용적, 직접 캐시 관리
- Write-Through: 일관성 중요할 때
- Write-Behind: 쓰기 성능 극대화
- Read-Through: Spring Cache 활용
운영 포인트:
- TTL 필수 설정
- maxmemory + eviction policy 설정
- Sentinel 또는 Cluster로 고가용성 확보
- Cache Stampede, Hot Key 대비
