Virtual Memory
왜 Virtual Memory가 필요한가
여러 프로세스가 동시에 실행되는 환경에서 각 프로세스는 자기가 할당받은 메모리에만 접근해야 한다. 다른 프로세스의 메모리를 읽거나 변경하면 안 된다. 보안 문제도 있고, 한 프로세스의 버그가 다른 프로세스를 죽일 수도 있으니까.
그런데 물리 메모리는 하나다. 모든 프로세스가 물리 주소를 직접 사용하면 어떻게 될까?
프로세스 A: 0x1000 번지에 데이터 저장
프로세스 B: 0x1000 번지에 데이터 저장 ← 충돌!
그래서 **Virtual Memory(가상 메모리)**가 필요하다. 각 프로세스에게 "너만의 메모리 공간이 있어"라고 착각하게 만드는 기술이다. 실제로는 물리 메모리를 공유하지만, 각 프로세스는 자기가 0번지부터 시작하는 전체 메모리를 혼자 쓰는 것처럼 느낀다.
주소 변환 (Address Translation)
프로세스가 사용하는 주소는 **가상 주소(Virtual Address)**다. 이걸 실제 **물리 주소(Physical Address)**로 변환해야 메모리에 접근할 수 있다.
이 변환을 하드웨어가 담당한다. CPU 안에 있는 **MMU(Memory Management Unit)**가 모든 메모리 접근을 가로채서 주소를 변환한다.
![]() MMU가 가상 주소를 물리 주소로 변환한다
MMU가 가상 주소를 물리 주소로 변환한다
Base/Limit Register 방식
가장 단순한 주소 변환 방식이다. CPU마다 두 개의 레지스터가 있다.
| 레지스터 | 역할 |
|---|---|
| Base Register | 프로세스 메모리의 시작 물리 주소 |
| Limit Register | 프로세스 메모리의 크기 |
변환 공식은 간단하다:
물리 주소 = 가상 주소 + Base Register
Limit Register는 보호를 위한 것이다. 가상 주소가 Limit보다 크면 예외가 발생한다. 다른 프로세스 영역을 침범하는 걸 막아준다.
예시: Base = 16KB, Limit = 16KB
가상 주소 8KB → 물리 주소 24KB (OK)
가상 주소 20KB → 예외 발생! (Limit 초과)
동적 재배치의 한계
Base/Limit 방식은 **동적 재배치(Dynamic Relocation)**라고 부른다. 프로세스 전체를 통째로 메모리에 배치한다.
문제는 **내부 단편화(Internal Fragmentation)**다.
프로세스 주소 공간: 4GB
실제 사용량: 100MB
낭비: 3.9GB ← 심각한 낭비
프로그램이 4GB 주소 공간을 선언했으면 실제로 100MB만 쓰더라도 4GB를 통째로 할당해야 한다. 코드, 힙, 스택 사이의 빈 공간이 전부 낭비된다.
Segmentation
내부 단편화를 해결하기 위해 등장한 게 Segmentation이다. 프로세스를 통째로 올리지 않고, 논리적 단위인 세그먼트로 쪼개서 올린다.
 프로세스 메모리 레이아웃 - Code, Data, Heap, Stack 세그먼트
프로세스 메모리 레이아웃 - Code, Data, Heap, Stack 세그먼트
세그먼트별로 Base/Limit이 따로 있다.
| 세그먼트 | Base | Limit |
|---|---|---|
| Code | 32KB | 2KB |
| Heap | 34KB | 3KB |
| Stack | 28KB | 2KB |
장점
사용하지 않는 영역은 메모리에 안 올려도 된다. 코드와 힙 사이의 빈 공간? 물리 메모리에 없다. 메모리 효율이 훨씬 좋아진다.
단점: 외부 단편화
세그먼트 크기가 제각각이다 보니 새로운 문제가 생긴다. 외부 단편화(External Fragmentation).
물리 메모리 상태:
[프로세스A 2KB][빈공간 1KB][프로세스B 3KB][빈공간 2KB][프로세스C 1KB]
→ 3KB 세그먼트를 넣고 싶은데, 연속된 3KB가 없다!
(빈 공간 총합은 3KB인데 조각나 있음)
해결책으로 **Compaction(압축)**이 있다. 메모리를 정리해서 빈 공간을 한쪽으로 모은다. 근데 이게 CPU와 메모리에 엄청난 부하를 준다. 실행 중인 프로세스를 전부 멈추고 메모리를 복사해야 하니까.
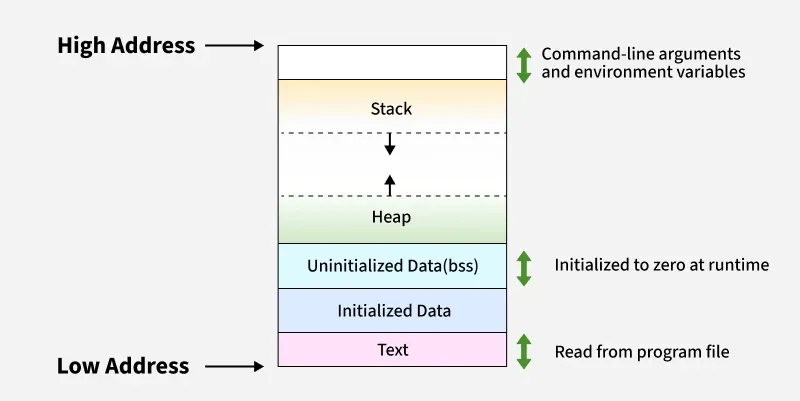
Paging
외부 단편화를 근본적으로 해결하는 방법이 Paging이다. 핵심 아이디어는 간단하다.
가상 메모리와 물리 메모리를 고정된 크기로 나누자
- Page: 가상 메모리를 나눈 단위 (보통 4KB)
- Frame: 물리 메모리를 나눈 단위 (Page와 동일 크기)
크기가 동일하니까 어떤 Page든 어떤 Frame에든 들어갈 수 있다. 연속적으로 배치할 필요가 없다.
 Paging - 가상 메모리의 Page가 물리 메모리의 Frame에 비연속적으로 매핑
Paging - 가상 메모리의 Page가 물리 메모리의 Frame에 비연속적으로 매핑
외부 단편화가 원천적으로 사라진다. Frame 크기가 고정이니까 "연속된 공간이 없어서 못 넣는" 상황이 없다.
Page Table
Page가 어떤 Frame에 매핑되어 있는지 기록하는 자료구조가 Page Table이다. 프로세스마다 하나씩 가지고 있다.
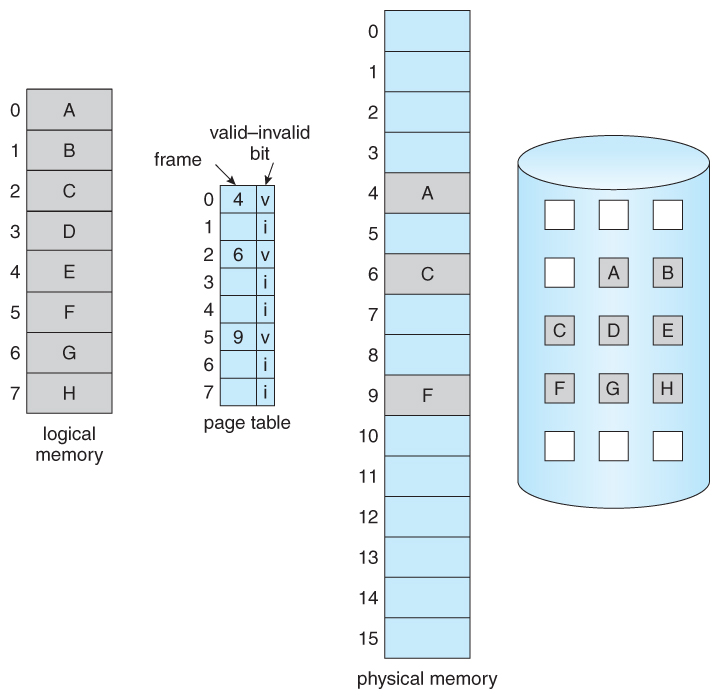 Page Table - 가상 페이지 번호를 물리 프레임 번호로 매핑
Page Table - 가상 페이지 번호를 물리 프레임 번호로 매핑
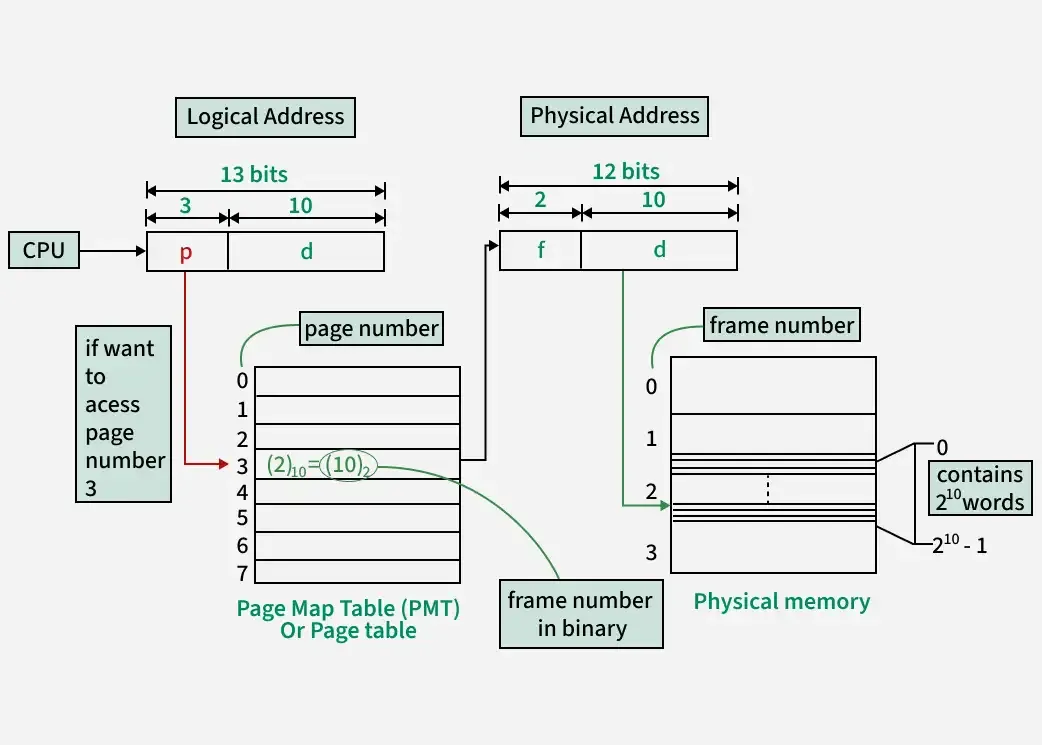
주소 변환 과정
가상 주소는 두 부분으로 나뉜다:
가상 주소 (32비트 예시, 4KB 페이지):
┌────────────────────┬──────────────┐
│ Page Number │ Offset │
│ (20비트) │ (12비트) │
└────────────────────┴──────────────┘
변환 과정:
1. Page Number로 Page Table 조회
2. Frame Number 획득
3. Frame Number + Offset = 물리 주소
예를 들어 가상 주소 0x00003ABC를 변환한다면:
- Page Number:
0x00003(3번 페이지) - Offset:
0xABC - Page Table에서 3번 → Frame 7번
- 물리 주소:
0x00007ABC
Page Table Entry (PTE)
Page Table의 각 항목에는 Frame 번호만 있는 게 아니다.
| 필드 | 설명 |
|---|---|
| Frame Number | 매핑된 물리 프레임 번호 |
| Valid Bit | 유효한 매핑인지 (메모리에 있는지) |
| Dirty Bit | 수정되었는지 (디스크에 써야 하는지) |
| Reference Bit | 최근에 접근되었는지 |
| Protection Bits | 읽기/쓰기/실행 권한 |
TLB (Translation Lookaside Buffer)
Page Table은 메모리에 있다. 모든 메모리 접근마다 Page Table을 먼저 읽어야 하니까, 메모리 접근이 2배가 된다. 이러면 너무 느리다.
그래서 TLB가 있다. Page Table의 캐시다.
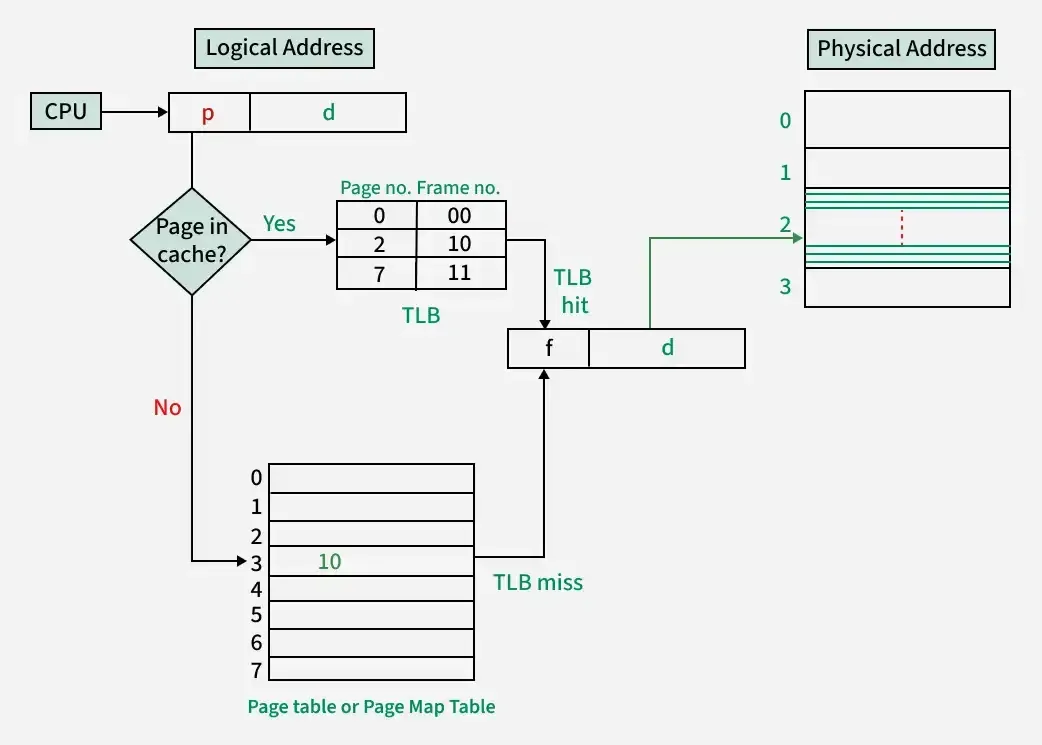 TLB - Page Table Entry를 캐싱해서 주소 변환을 가속
TLB - Page Table Entry를 캐싱해서 주소 변환을 가속
TLB Hit vs Miss
TLB Hit (빠름):
CPU → TLB 조회 → Frame 번호 획득 → 메모리 접근
TLB Miss (느림):
CPU → TLB 조회(실패) → Page Table 조회 → TLB 갱신 → 메모리 접근
TLB Hit Rate가 높으면 성능이 좋다. 다행히 프로그램은 **지역성(Locality)**이 있어서 Hit Rate가 보통 95% 이상이다.
| 지역성 유형 | 설명 |
|---|---|
| 시간적 지역성 | 최근 접근한 주소를 다시 접근할 가능성 높음 |
| 공간적 지역성 | 인접한 주소를 접근할 가능성 높음 |
한 페이지 안의 여러 주소를 접근하면 TLB 항목 하나로 전부 커버된다 (Page 크기가 4KB니까).
Page Fault
Page Table의 Valid Bit가 0이면? 해당 페이지가 메모리에 없다는 뜻이다. 디스크에 있거나, 아직 할당되지 않았거나.
이때 Page Fault 예외가 발생한다.
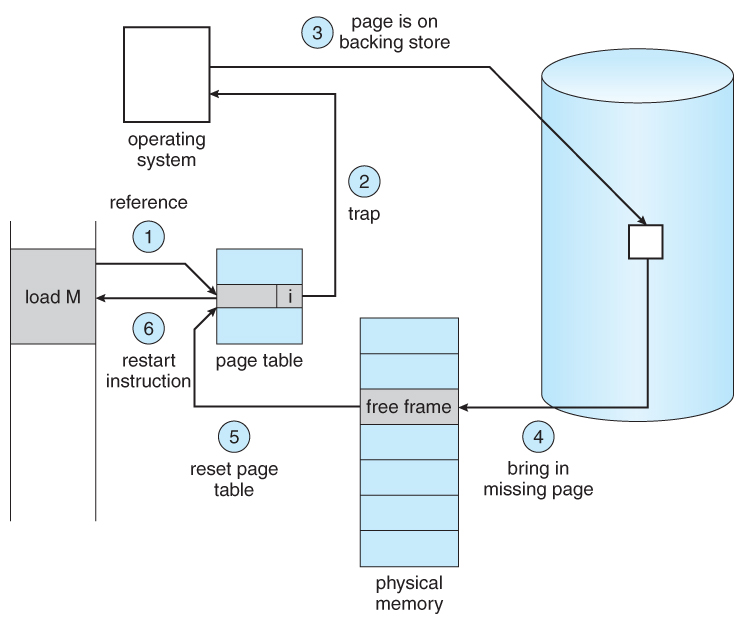 Page Fault 처리 과정 - 디스크에서 페이지를 가져온다
Page Fault 처리 과정 - 디스크에서 페이지를 가져온다
Page Fault 처리 과정
- CPU가 가상 주소 접근 시도
- Page Table 확인 → Valid Bit = 0
- Page Fault 예외 발생
- OS의 Page Fault Handler 실행
- 디스크에서 해당 페이지 읽기
- 빈 Frame에 로드
- Page Table 갱신 (Valid = 1, Frame 번호 기록)
- 중단된 명령어 재실행
Page Fault는 디스크 I/O가 필요해서 매우 느리다. 메모리 접근이 수십 나노초라면, 디스크 접근은 수 밀리초다. 수만 배 차이.
Page Replacement
물리 메모리가 꽉 찼는데 새 페이지를 올려야 한다면? 기존 페이지 중 하나를 Victim으로 선정해서 내보내야 한다.
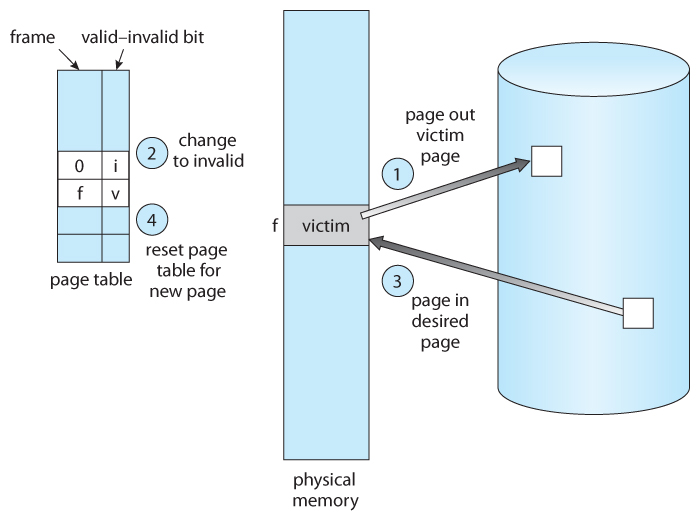 Page Replacement - Victim 페이지를 디스크로 내보내고 새 페이지를 로드
Page Replacement - Victim 페이지를 디스크로 내보내고 새 페이지를 로드
Dirty Page 처리
Victim 페이지가 수정되었으면 (Dirty Bit = 1) 디스크에 먼저 써야 한다. 수정 안 됐으면 그냥 버리면 된다 (디스크에 원본이 있으니까).
Dirty Page → 디스크 쓰기 후 Frame 재사용
Clean Page → 바로 Frame 재사용
Page Replacement 알고리즘
어떤 페이지를 Victim으로 선택하느냐에 따라 성능이 달라진다.
| 알고리즘 | 설명 | 특징 |
|---|---|---|
| FIFO | 가장 먼저 들어온 페이지 교체 | 구현 간단, 성능 나쁨 |
| LRU | 가장 오래 안 쓴 페이지 교체 | 성능 좋음, 구현 복잡 |
| LFU | 가장 적게 쓴 페이지 교체 | 최근 로드된 페이지에 불리 |
| Clock | LRU 근사, Reference Bit 활용 | 실용적 |
Optimal 알고리즘은 "앞으로 가장 오래 안 쓸 페이지"를 교체한다. 이론상 최적이지만 미래를 알 수 없으니 실제로는 불가능하다. 다른 알고리즘의 비교 기준으로만 쓴다.
Thrashing
Page Fault가 너무 자주 발생하면 시스템이 거의 멈춘다. CPU는 대부분의 시간을 페이지 교체에 쓰고, 실제 작업은 거의 못 한다. 이걸 Thrashing이라고 한다.
프로세스 수 ↑ → 각 프로세스 Frame 수 ↓ → Page Fault ↑ → Thrashing
Working Set
Thrashing을 방지하려면 각 프로세스가 Working Set(현재 활발히 사용하는 페이지 집합)만큼의 Frame을 확보해야 한다.
Working Set 크기보다 할당된 Frame이 적으면 Page Fault가 급증한다. OS는 Working Set을 추정해서 메모리를 할당한다.
Multi-Level Page Table
32비트 시스템에서 4KB 페이지를 쓰면 Page Table 크기가 얼마일까?
가상 주소 공간: 4GB = 2^32 바이트
페이지 크기: 4KB = 2^12 바이트
페이지 개수: 2^32 / 2^12 = 2^20 = 약 100만 개
PTE 크기: 4바이트
Page Table 크기: 4MB (프로세스마다!)
프로세스 100개면 Page Table만 400MB다. 대부분의 프로세스는 4GB 주소 공간을 다 안 쓰는데, Page Table은 전체 크기로 만들어야 한다.
해결책은 Multi-Level Page Table이다.
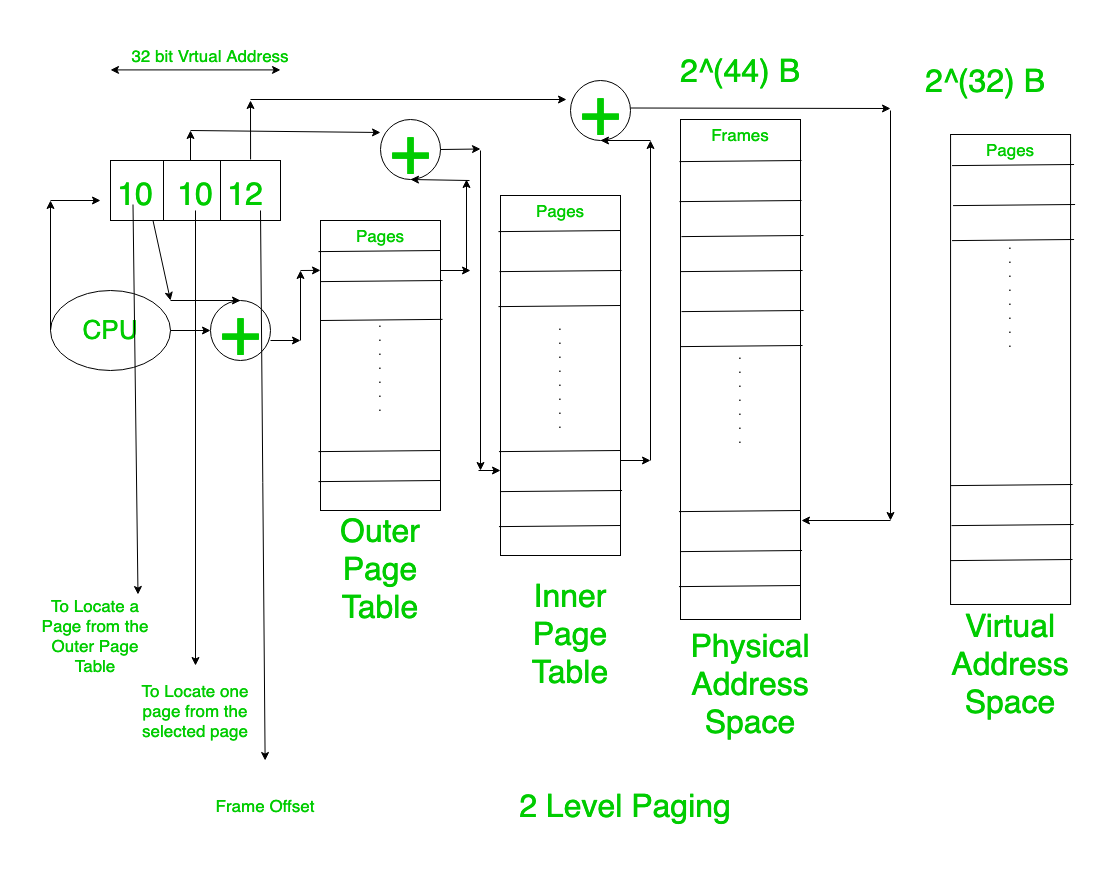 Multi-Level Page Table - 사용하지 않는 영역의 하위 테이블은 생성하지 않아 메모리 절약
Multi-Level Page Table - 사용하지 않는 영역의 하위 테이블은 생성하지 않아 메모리 절약
사용하지 않는 영역의 L2 Table은 아예 만들지 않는다. 메모리 절약이 크다.
정리
Virtual Memory는 현대 운영체제의 핵심이다.
- 가상 주소 공간으로 프로세스 격리
- Paging으로 외부 단편화 해결, 고정 크기 Page/Frame
- Page Table로 가상→물리 주소 변환
- TLB로 주소 변환 가속
- Page Fault로 요청 시 페이지 로드 (Demand Paging)
- Page Replacement 알고리즘으로 Victim 선택
- Multi-Level Page Table로 메모리 효율화
