Spring Batch Step 파헤쳐보기
Step이란?
Step은 Batch Job을 구성하는 독립적인 실행 단위다. 하나의 Job은 최소 하나 이상의 Step으로 구성되며, 각 Step은 실제 배치 처리를 정의하고 제어하는 모든 정보를 담고 있다.
Step을 이해하기 위해 Spring Batch의 전체 아키텍처를 먼저 살펴보자.
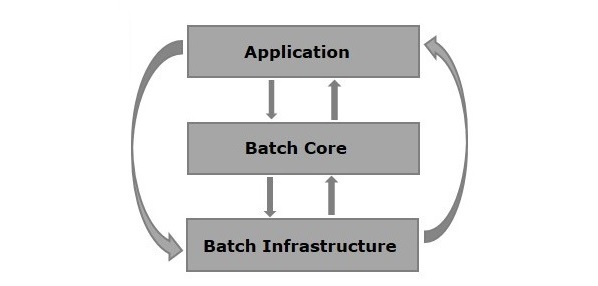 Spring Batch 아키텍처 - Application, Batch Core, Batch Infrastructure 3계층 구조
Spring Batch 아키텍처 - Application, Batch Core, Batch Infrastructure 3계층 구조
Spring Batch Job 구현체 중 하나인 SimpleJob의 내부를 보면 Job이 Step 리스트를 멤버변수로 가지고 있음을 확인할 수 있다.
public class SimpleJob extends AbstractJob {
private List<Step> steps = new ArrayList<>();
// ...
}
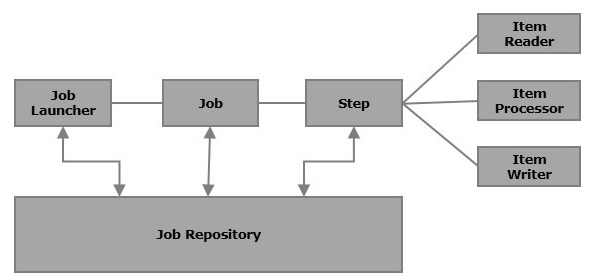 Spring Batch 주요 컴포넌트 - Job과 Step의 관계
Spring Batch 주요 컴포넌트 - Job과 Step의 관계
Spring Batch에서 제공하는 Step 구현체
Step 인터페이스를 AbstractStep 추상 클래스가 구현하고, 이를 상속받는 5가지 구현체가 존재한다.
| Step 구현체 | 설명 | 주요 용도 |
|---|---|---|
| TaskletStep | 가장 기본적인 Step. Tasklet 구현체를 실행 | 단순 작업, Chunk 기반 처리 |
| PartitionStep | 데이터를 파티셔닝하여 병렬 처리 | 대용량 데이터 병렬 처리 |
| JobStep | Step 내부에 또 다른 Job을 포함 | Job 분리 및 재사용 |
| FlowStep | Flow를 실행하는 Step | 복잡한 흐름 제어 |
| JobExecutionDecider | 조건에 따라 분기 결정 (Step이 아닌 인터페이스) | 동적 흐름 결정 |
StepExecution - Step 실행 정보
StepExecution은 Step에 대한 한 번의 실행 시도를 나타내는 객체다. Step이 실행될 때마다 새로운 StepExecution이 생성되며, 실행 중 발생한 모든 정보를 저장한다.
StepExecution의 주요 속성
public class StepExecution extends Entity {
private final JobExecution jobExecution; // 소속된 JobExecution
private final String stepName; // Step 이름
private volatile BatchStatus status; // 실행 상태
private volatile int readCount; // 읽은 아이템 수
private volatile int writeCount; // 쓴 아이템 수
private volatile int commitCount; // 커밋 횟수
private volatile int rollbackCount; // 롤백 횟수
private volatile int readSkipCount; // 읽기 스킵 수
private volatile int processSkipCount; // 처리 스킵 수
private volatile int writeSkipCount; // 쓰기 스킵 수
private volatile int filterCount; // 필터링된 아이템 수
private volatile Date startTime; // 시작 시간
private volatile Date endTime; // 종료 시간
private volatile ExecutionContext executionContext; // 실행 컨텍스트
private volatile ExitStatus exitStatus; // 종료 상태
// ...
}
재시작 시 StepExecution 동작
Job이 실패해서 재실행하는 경우, 기본적으로 실패한 Step부터 재시작된다.
첫 번째 실행:
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Step 1 │ -> │ Step 2 │ -> │ Step 3 │
│ COMPLETED │ │ FAILED │ │ 미실행 │
└─────────────┘ └─────────────┘ └─────────────┘
재실행 (Job 재시작):
┌─────────────┐ ┌─────────────┐
│ Step 2 │ -> │ Step 3 │
│ 재시작 │ │ 실행 │
└─────────────┘ └─────────────┘
Step 1은 이미 성공했으므로 생략되고, 실패한 Step 2부터 재시작된다. 단, allowStartIfComplete(true) 설정 시 성공한 Step도 재시작할 수 있다.
DB 테이블 매핑
StepExecution은 BATCH_STEP_EXECUTION 테이블과 1:1로 매핑된다.
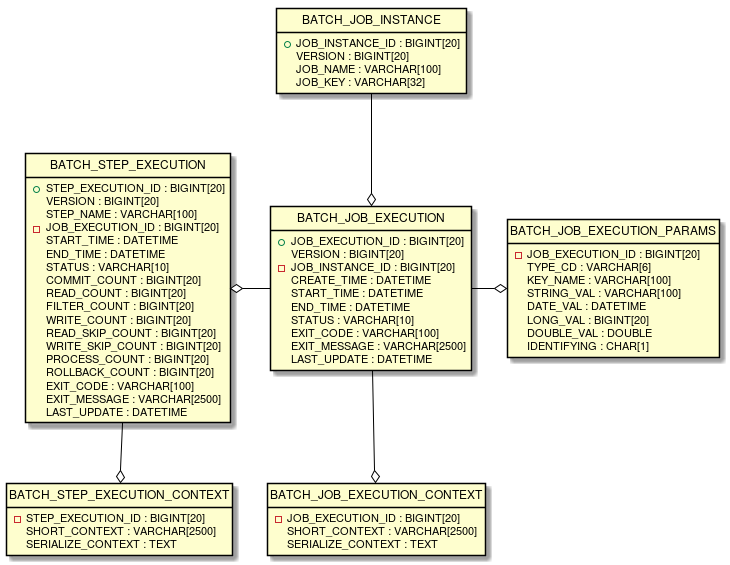 Spring Batch 메타데이터 ERD - Job, Step, Execution 관계
Spring Batch 메타데이터 ERD - Job, Step, Execution 관계
ExecutionContext - Step 간 데이터 공유
ExecutionContext는 Spring Batch가 관리하는 key-value 저장소다. Step 간 데이터 공유나 재시작 시 이전 상태 복원에 활용된다.
ExecutionContext 범위
| ExecutionContext | 범위 | DB 테이블 |
|---|---|---|
| JobExecution 내 | 모든 Step에서 공유 | BATCH_JOB_EXECUTION_CONTEXT |
| StepExecution 내 | 해당 Step 내에서만 접근 | BATCH_STEP_EXECUTION_CONTEXT |
사용 예시 (Spring Batch 5.x)
@Bean
public Step contextSharingStep(JobRepository jobRepository,
PlatformTransactionManager transactionManager) {
return new StepBuilder("contextSharingStep", jobRepository)
.tasklet((contribution, chunkContext) -> {
// JobExecution의 ExecutionContext (모든 Step에서 공유)
ExecutionContext jobContext = contribution.getStepExecution()
.getJobExecution()
.getExecutionContext();
// StepExecution의 ExecutionContext (현재 Step에서만 접근)
ExecutionContext stepContext = contribution.getStepExecution()
.getExecutionContext();
jobContext.put("sharedData", "모든 Step에서 접근 가능");
stepContext.put("stepLocalData", "현재 Step에서만 접근 가능");
return RepeatStatus.FINISHED;
}, transactionManager)
.build();
}
다른 Step에서 공유 데이터 접근:
@Bean
public Step readSharedDataStep(JobRepository jobRepository,
PlatformTransactionManager transactionManager) {
return new StepBuilder("readSharedDataStep", jobRepository)
.tasklet((contribution, chunkContext) -> {
ExecutionContext jobContext = contribution.getStepExecution()
.getJobExecution()
.getExecutionContext();
String sharedData = jobContext.getString("sharedData");
System.out.println("공유 데이터: " + sharedData); // "모든 Step에서 접근 가능"
return RepeatStatus.FINISHED;
}, transactionManager)
.build();
}
TaskletStep - 가장 기본적인 Step
TaskletStep은 Tasklet 인터페이스 구현체를 실행하는 Step이다. Spring Batch에서 가장 많이 사용되는 Step 유형이다.
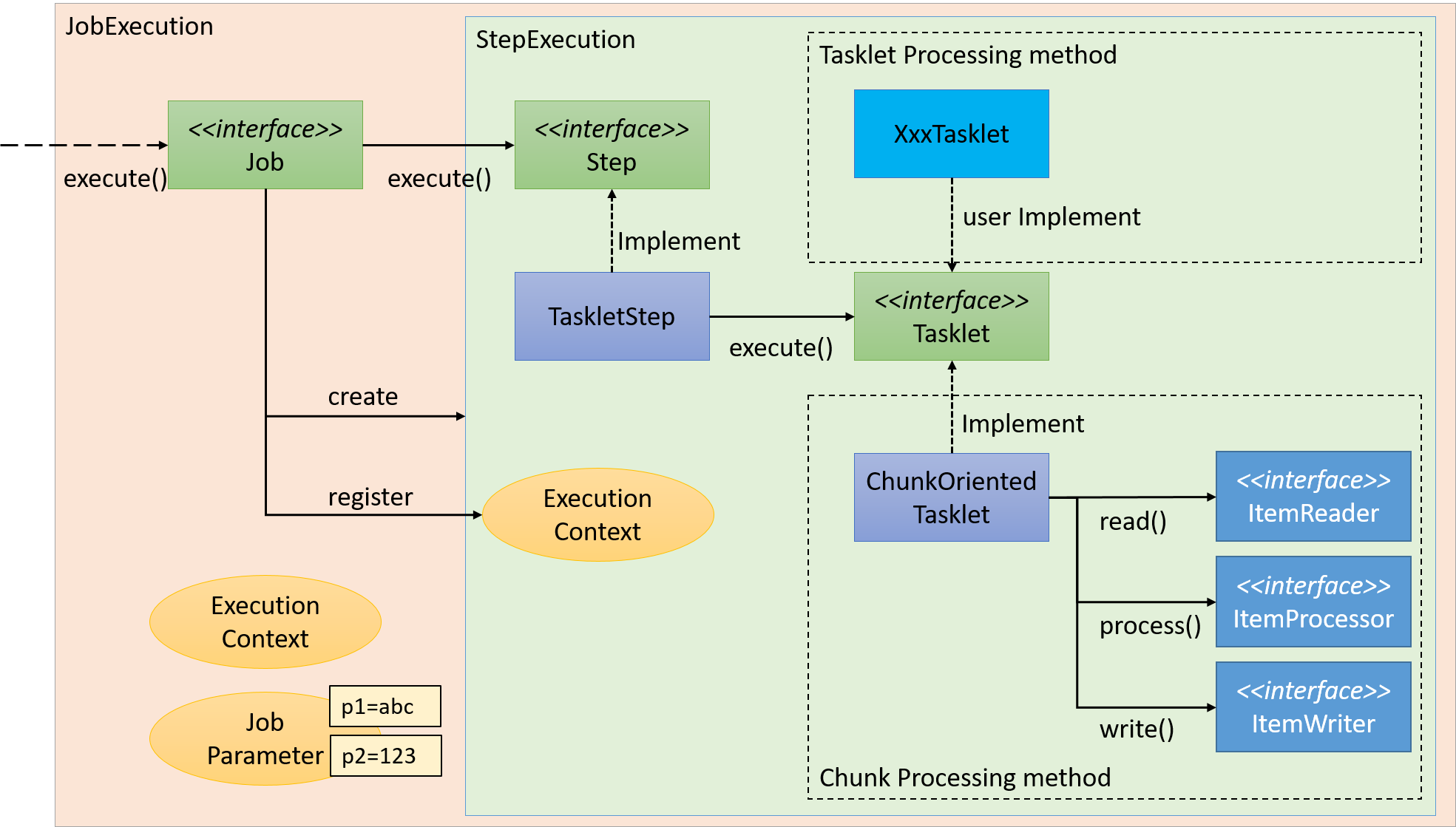 Step과 Tasklet의 실행 흐름
Step과 Tasklet의 실행 흐름
Tasklet 인터페이스
@FunctionalInterface
public interface Tasklet {
/**
* @return RepeatStatus.FINISHED: 작업 완료, RepeatStatus.CONTINUABLE: 재실행
*/
@Nullable
RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext)
throws Exception;
}
RepeatTemplate이 Tasklet을 트랜잭션 경계 내에서 반복 실행하며, RepeatStatus.FINISHED를 반환할 때까지 계속 실행한다.
Task 기반 vs Chunk 기반
TaskletStep은 두 가지 방식으로 구현할 수 있다.
| 구분 | Task 기반 | Chunk 기반 |
|---|---|---|
| 처리 방식 | 단일 작업으로 처리 | 데이터를 Chunk 단위로 분할 처리 |
| 주요 용도 | 파일 삭제, 리소스 정리 등 | 대용량 데이터 읽기/처리/쓰기 |
| 구현 방법 | Tasklet 직접 구현 | ItemReader, ItemProcessor, ItemWriter |
| 트랜잭션 | 전체가 하나의 트랜잭션 | Chunk 단위로 트랜잭션 커밋 |
Task 기반 Tasklet
단순하고 독립적인 작업에 적합하다. 직접 Tasklet 인터페이스를 구현한다.
@Configuration
@RequiredArgsConstructor
public class TaskBasedStepConfig {
private final JobRepository jobRepository;
private final PlatformTransactionManager transactionManager;
@Bean
public Step cleanupStep() {
return new StepBuilder("cleanupStep", jobRepository)
.tasklet((contribution, chunkContext) -> {
// 임시 파일 정리 로직
Path tempDir = Paths.get("/tmp/batch-work");
if (Files.exists(tempDir)) {
Files.walk(tempDir)
.sorted(Comparator.reverseOrder())
.map(Path::toFile)
.forEach(File::delete);
}
return RepeatStatus.FINISHED;
}, transactionManager)
.build();
}
@Bean
public Step notificationStep() {
return new StepBuilder("notificationStep", jobRepository)
.tasklet(new SlackNotificationTasklet(), transactionManager)
.build();
}
}
public class SlackNotificationTasklet implements Tasklet {
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) {
JobExecution jobExecution = contribution.getStepExecution().getJobExecution();
String message = String.format("Job [%s] 완료. 상태: %s",
jobExecution.getJobInstance().getJobName(),
jobExecution.getStatus());
// Slack 알림 발송 로직
sendSlackMessage(message);
return RepeatStatus.FINISHED;
}
private void sendSlackMessage(String message) {
// Slack API 호출
}
}
Chunk 기반 Tasklet - ChunkOrientedTasklet
대용량 데이터 처리의 핵심이다. 데이터를 일정 크기(Chunk)로 나누어 처리하고, Chunk 단위로 트랜잭션을 커밋한다.
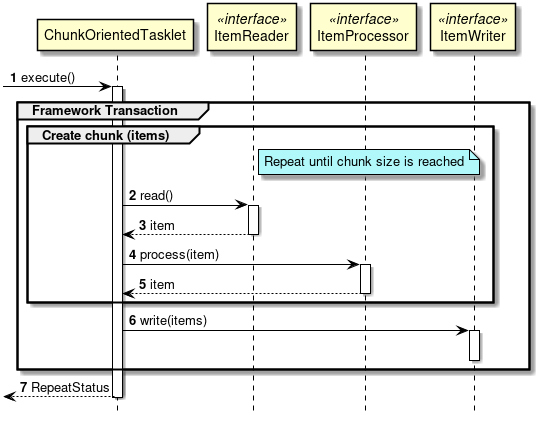 ChunkOrientedTasklet 처리 시퀀스 - Read, Process, Write 흐름
ChunkOrientedTasklet 처리 시퀀스 - Read, Process, Write 흐름
Chunk 처리 흐름
┌────────────────────────────────────────────────────────────┐
│ Chunk 처리 루프 │
├────────────────────────────────────────────────────────────┤
│ 1. ItemReader.read() 호출 (chunk-size 만큼 반복) │
│ └─> 아이템을 하나씩 읽어 리스트에 저장 │
│ │
│ 2. ItemProcessor.process() 호출 (읽은 아이템 수만큼) │
│ └─> 각 아이템을 변환/가공 │
│ │
│ 3. ItemWriter.write() 호출 (1회) │
│ └─> 처리된 chunk 전체를 한 번에 쓰기 │
│ │
│ 4. 트랜잭션 커밋 │
└────────────────────────────────────────────────────────────┘
↓ ItemReader가 null 반환할 때까지 반복
Chunk 기반 Step 구현 (Spring Batch 5.x)
@Configuration
@RequiredArgsConstructor
public class ChunkBasedStepConfig {
private final JobRepository jobRepository;
private final PlatformTransactionManager transactionManager;
private final DataSource dataSource; // HikariCP 등에서 주입
@Bean
public Step processOrdersStep() {
return new StepBuilder("processOrdersStep", jobRepository)
.<Order, ProcessedOrder>chunk(100, transactionManager) // chunk-size: 100
.reader(orderReader())
.processor(orderProcessor())
.writer(orderWriter())
.build();
}
@Bean
public ItemReader<Order> orderReader() {
return new JdbcCursorItemReaderBuilder<Order>()
.name("orderReader")
.dataSource(dataSource)
.sql("SELECT id, customer_id, amount, status FROM orders WHERE status = 'PENDING'")
.rowMapper(new OrderRowMapper())
.build();
}
@Bean
public ItemProcessor<Order, ProcessedOrder> orderProcessor() {
return order -> {
// 비즈니스 로직 적용
double discountedAmount = order.getAmount() * 0.9;
return new ProcessedOrder(order.getId(), discountedAmount, "PROCESSED");
};
}
@Bean
public ItemWriter<ProcessedOrder> orderWriter() {
return new JdbcBatchItemWriterBuilder<ProcessedOrder>()
.dataSource(dataSource)
.sql("UPDATE orders SET amount = :amount, status = :status WHERE id = :id")
.beanMapped()
.build();
}
}
chunk-size 설정 가이드
chunk-size는 성능에 직접적인 영향을 미친다.
| chunk-size | 장점 | 단점 |
|---|---|---|
| 작은 값 (10~50) | 메모리 사용량 적음, 빠른 실패 감지 | 커밋 오버헤드 증가 |
| 큰 값 (500~1000) | 처리량 증가, 커밋 오버헤드 감소 | 메모리 사용량 증가, 롤백 범위 증가 |
일반적으로 100~500 사이에서 시작하고, 실제 데이터와 시스템 환경에 맞게 튜닝한다.
StepContribution - Chunk 작업 버퍼링
StepContribution은 Chunk 처리 과정의 변경 사항을 임시 저장(버퍼링)한다. Chunk 커밋 직전에 StepExecution에 반영된다.
public class StepExecution extends Entity {
/**
* Chunk 커밋 직전에 호출되어 StepContribution의 값을 누적
*/
public synchronized void apply(StepContribution contribution) {
readSkipCount += contribution.getReadSkipCount();
writeSkipCount += contribution.getWriteSkipCount();
processSkipCount += contribution.getProcessSkipCount();
filterCount += contribution.getFilterCount();
readCount += contribution.getReadCount();
writeCount += contribution.getWriteCount();
exitStatus = exitStatus.and(contribution.getExitStatus());
}
}
이 구조 덕분에 Chunk 처리 중 실패해도 이전 Chunk까지의 진행 상황은 안전하게 보존된다.
Step 재시작 제어 API
startLimit - 재시작 횟수 제한
Step 실패 시 재시작할 수 있는 최대 횟수를 제한한다.
@Bean
public Step limitedRetryStep(JobRepository jobRepository,
PlatformTransactionManager transactionManager) {
return new StepBuilder("limitedRetryStep", jobRepository)
.tasklet((contribution, chunkContext) -> {
// 외부 API 호출 등 실패 가능한 작업
callExternalApi();
return RepeatStatus.FINISHED;
}, transactionManager)
.startLimit(3) // 최대 3번까지만 재시작 허용
.build();
}
3번 재시작 후에도 실패하면 StartLimitExceededException이 발생한다.
재시작 1회차: Step 실행 -> FAILED
재시작 2회차: Step 실행 -> FAILED
재시작 3회차: Step 실행 -> FAILED
재시작 4회차: StartLimitExceededException 발생!
allowStartIfComplete - 완료된 Step 재실행
기본적으로 성공한 Step은 재시작 시 건너뛴다. allowStartIfComplete(true)로 설정하면 성공한 Step도 재실행한다.
@Bean
public Step dataValidationStep(JobRepository jobRepository,
PlatformTransactionManager transactionManager) {
return new StepBuilder("dataValidationStep", jobRepository)
.tasklet((contribution, chunkContext) -> {
// 데이터 유효성 검증 - 매번 실행 필요
validateData();
return RepeatStatus.FINISHED;
}, transactionManager)
.allowStartIfComplete(true) // 성공해도 재시작 시 다시 실행
.build();
}
활용 사례:
- 시점에 따라 결과가 달라지는 데이터 유효성 검증
- 외부 시스템 상태 확인
- 매 실행마다 최신 데이터 동기화가 필요한 경우
조합 예시
@Bean
public Job robustBatchJob(JobRepository jobRepository,
PlatformTransactionManager transactionManager) {
return new JobBuilder("robustBatchJob", jobRepository)
.start(validationStep(jobRepository, transactionManager))
.next(processingStep(jobRepository, transactionManager))
.next(cleanupStep(jobRepository, transactionManager))
.build();
}
@Bean
public Step validationStep(JobRepository jobRepository,
PlatformTransactionManager transactionManager) {
return new StepBuilder("validationStep", jobRepository)
.tasklet(validationTasklet(), transactionManager)
.allowStartIfComplete(true) // 재시작 시에도 항상 검증
.build();
}
@Bean
public Step processingStep(JobRepository jobRepository,
PlatformTransactionManager transactionManager) {
return new StepBuilder("processingStep", jobRepository)
.<Data, Data>chunk(100, transactionManager)
.reader(dataReader())
.processor(dataProcessor())
.writer(dataWriter())
.startLimit(5) // 최대 5회까지 재시작
.build();
}
JobStep - Step 안의 Job
JobStep은 Step 내부에 별도의 Job을 포함시킨다. 큰 Job을 논리적으로 분리하거나, 재사용 가능한 Job을 조합할 때 유용하다.
@Configuration
@RequiredArgsConstructor
public class JobStepConfig {
private final JobRepository jobRepository;
private final PlatformTransactionManager transactionManager;
private final JobLauncher jobLauncher;
@Bean
public Job parentJob() {
return new JobBuilder("parentJob", jobRepository)
.start(childJobStep())
.next(postProcessingStep())
.build();
}
@Bean
public Step childJobStep() {
return new StepBuilder("childJobStep", jobRepository)
.job(childJob())
.launcher(jobLauncher)
.parametersExtractor(jobParametersExtractor())
.build();
}
@Bean
public Job childJob() {
return new JobBuilder("childJob", jobRepository)
.start(childStep1())
.next(childStep2())
.build();
}
/**
* 부모 Job의 파라미터나 ExecutionContext에서 값을 추출하여
* 자식 Job에 전달
*/
@Bean
public DefaultJobParametersExtractor jobParametersExtractor() {
DefaultJobParametersExtractor extractor = new DefaultJobParametersExtractor();
extractor.setKeys(new String[]{"inputFile", "outputDir"});
return extractor;
}
}
JobStep 실행 결과에 따른 상태
| 시나리오 | Child Job 상태 | Parent Job 상태 |
|---|---|---|
| 모두 성공 | COMPLETED | COMPLETED |
| Child Job 실패 | FAILED | FAILED |
| Child 성공, Parent의 다른 Step 실패 | COMPLETED | FAILED |
Child Job은 별도의 JobInstance로 관리되므로, Child Job이 성공하면 Parent Job 재시작 시 Child Job은 다시 실행되지 않는다.
PartitionStep - 병렬 처리
대용량 데이터를 파티션으로 나누어 병렬 처리한다. 각 파티션은 독립적인 StepExecution으로 실행된다.
@Bean
public Step partitionedStep(JobRepository jobRepository,
PlatformTransactionManager transactionManager) {
return new StepBuilder("partitionedStep", jobRepository)
.partitioner("workerStep", rangePartitioner())
.step(workerStep(jobRepository, transactionManager))
.gridSize(4) // 4개 파티션으로 분할
.taskExecutor(taskExecutor())
.build();
}
@Bean
public Partitioner rangePartitioner() {
return gridSize -> {
Map<String, ExecutionContext> partitions = new HashMap<>();
int totalRecords = getTotalCount();
int range = totalRecords / gridSize;
for (int i = 0; i < gridSize; i++) {
ExecutionContext context = new ExecutionContext();
context.putInt("minId", i * range + 1);
context.putInt("maxId", (i + 1) * range);
partitions.put("partition" + i, context);
}
return partitions;
};
}
@Bean
public Step workerStep(JobRepository jobRepository,
PlatformTransactionManager transactionManager) {
return new StepBuilder("workerStep", jobRepository)
.<Data, Data>chunk(100, transactionManager)
.reader(partitionedReader(null, null)) // @StepScope로 파티션 값 주입
.processor(processor())
.writer(writer())
.build();
}
@Bean
@StepScope
public JdbcCursorItemReader<Data> partitionedReader(
@Value("#{stepExecutionContext['minId']}") Integer minId,
@Value("#{stepExecutionContext['maxId']}") Integer maxId) {
return new JdbcCursorItemReaderBuilder<Data>()
.name("partitionedReader")
.dataSource(dataSource)
.sql("SELECT * FROM data WHERE id BETWEEN ? AND ?")
.preparedStatementSetter(ps -> {
ps.setInt(1, minId);
ps.setInt(2, maxId);
})
.rowMapper(new DataRowMapper())
.build();
}
FlowStep - 복잡한 흐름 제어
여러 Step을 Flow로 그룹화하여 재사용하거나, 조건부 분기를 구현한다.
@Bean
public Job flowBasedJob(JobRepository jobRepository) {
return new JobBuilder("flowBasedJob", jobRepository)
.start(preprocessingFlow())
.next(mainProcessingStep())
.end()
.build();
}
@Bean
public Flow preprocessingFlow() {
return new FlowBuilder<SimpleFlow>("preprocessingFlow")
.start(validateInputStep())
.next(backupStep())
.build();
}
// 조건부 분기
@Bean
public Job conditionalJob(JobRepository jobRepository) {
return new JobBuilder("conditionalJob", jobRepository)
.start(decisionStep())
.on("VALID").to(processStep())
.from(decisionStep())
.on("INVALID").to(errorHandlingStep())
.from(decisionStep())
.on("*").to(defaultStep())
.end()
.build();
}
실전 팁
1. Step 설계 원칙
✓ 하나의 Step은 하나의 책임만
✓ Step 간 의존성을 최소화
✓ 실패 시 재시작 가능하도록 멱등성 보장
✓ 진행 상황을 ExecutionContext에 저장하여 재시작 시 복원
2. Chunk-size 튜닝
// 메모리 사용량 모니터링하며 조정
@Bean
public Step tunedChunkStep(JobRepository jobRepository,
PlatformTransactionManager transactionManager) {
return new StepBuilder("tunedChunkStep", jobRepository)
.<Data, Data>chunk(
getOptimalChunkSize(), // 환경 변수나 설정에서 동적으로
transactionManager)
.reader(reader())
.writer(writer())
.build();
}
private int getOptimalChunkSize() {
// 시스템 메모리, 레코드 크기 등을 고려하여 결정
return Integer.parseInt(System.getProperty("batch.chunk.size", "100"));
}
3. Step 리스너 활용
@Bean
public Step monitoredStep(JobRepository jobRepository,
PlatformTransactionManager transactionManager) {
return new StepBuilder("monitoredStep", jobRepository)
.<Data, Data>chunk(100, transactionManager)
.reader(reader())
.writer(writer())
.listener(new StepExecutionListener() {
@Override
public void beforeStep(StepExecution stepExecution) {
log.info("Step 시작: {}", stepExecution.getStepName());
}
@Override
public ExitStatus afterStep(StepExecution stepExecution) {
log.info("Step 완료: {} - 읽음: {}, 씀: {}",
stepExecution.getStepName(),
stepExecution.getReadCount(),
stepExecution.getWriteCount());
return stepExecution.getExitStatus();
}
})
.build();
}
자주 묻는 질문 (FAQ)
Q1: Chunk-size는 얼마로 설정해야 하나요?
일반적으로 100~500 사이에서 시작한다. 레코드 크기가 크면 작게, 작으면 크게 설정한다. 실제 환경에서 메모리 사용량과 처리 시간을 모니터링하며 튜닝하는 것이 좋다.
Q2: Task 기반과 Chunk 기반 중 어떤 것을 선택해야 하나요?
- Task 기반: 파일 삭제, 알림 발송 등 단순하고 독립적인 작업
- Chunk 기반: 대량의 데이터를 읽고, 처리하고, 저장하는 ETL 작업
Q3: Step 실패 시 자동 재시도는 어떻게 하나요?
faultTolerant()와 retry()를 사용한다:
@Bean
public Step retryableStep(JobRepository jobRepository,
PlatformTransactionManager transactionManager) {
return new StepBuilder("retryableStep", jobRepository)
.<Data, Data>chunk(100, transactionManager)
.reader(reader())
.processor(processor())
.writer(writer())
.faultTolerant()
.retry(TransientException.class)
.retryLimit(3)
.build();
}
Q4: ExecutionContext에 저장할 수 있는 데이터 크기 제한이 있나요?
DB 컬럼 크기에 따라 제한된다. 기본적으로 직렬화된 JSON 형태로 저장되므로, 너무 큰 데이터는 외부 저장소(Redis, S3 등)를 활용하고 ExecutionContext에는 참조 키만 저장하는 것이 좋다.
Q5: allowStartIfComplete와 startLimit을 동시에 사용할 수 있나요?
가능하다. allowStartIfComplete(true)는 성공한 Step을 재실행할지 결정하고, startLimit은 실패한 Step의 재시작 횟수를 제한한다. 두 설정은 독립적으로 동작한다.
Q6: ItemProcessor에서 null을 반환하면 어떻게 되나요?
해당 아이템은 필터링되어 ItemWriter로 전달되지 않는다. filterCount가 1 증가하고 다음 아이템 처리로 넘어간다. 조건부로 아이템을 건너뛸 때 유용하다.
Q7: Chunk 처리 중 특정 아이템에서 예외가 발생하면?
기본적으로 해당 Chunk 전체가 롤백된다. faultTolerant()와 skip()을 설정하면 특정 예외 발생 시 해당 아이템만 건너뛰고 나머지는 정상 처리할 수 있다.
Q8: StepBuilderFactory에서 StepBuilder로 마이그레이션하려면?
Spring Batch 5.0부터 StepBuilderFactory가 deprecated되었다. new StepBuilder("stepName", jobRepository)로 직접 생성하고, transactionManager를 tasklet이나 chunk 메서드에 전달하면 된다.
참고문헌
- Spring Batch Reference - Configuring a Step - 공식 문서
- TERASOLUNA Batch Framework Guideline - 아키텍처 상세
- Spring Batch - Chunk-oriented Processing - Chunk 처리 공식 가이드
