OpenTelemetry + LGTM 스택 (Loki, Grafana, Tempo, Mimir) 정리
왜 LGTM 스택인가?
기존에는 모니터링을 위해 Prometheus만 쓰거나, 로그는 ELK Stack, 분산 트레이싱은 Jaeger 이런 식으로 각각 따로 운영했다. 근데 이게 문제가 있다.
서비스에서 장애가 발생했을 때 Prometheus에서 메트릭을 확인하고, 문제가 있는 시간대의 로그를 Kibana에서 찾고, 다시 Jaeger로 가서 해당 요청의 Trace를 확인하는 식이다. 도구가 분산되어 있으니까 문제 원인을 찾는 데 시간이 오래 걸린다.
LGTM 스택은 Traces, Metrics, Logs 세 가지를 하나의 플랫폼에서 통합해서 보는 것이다. 하나의 대시보드에서 메트릭 이상을 발견하면 클릭 한 번으로 해당 시점의 로그와 트레이스로 바로 이동할 수 있다.
기존 방식: Metrics(Prometheus) → Logs(Kibana) → Traces(Jaeger) → 각각 별도 조회
LGTM 스택: Grafana 하나에서 Metrics → Logs → Traces 연결
관측성의 세 가지 기둥 (Three Pillars)
관측성은 세 가지 신호(signal)로 구성된다.
| 신호 타입 | 역할 | 예시 |
|---|---|---|
| Metrics | 시스템의 수치적 상태 | CPU 사용률, 요청 처리 시간, 에러율 |
| Logs | 이벤트 기록 | 에러 스택 트레이스, 비즈니스 로직 실행 내역 |
| Traces | 요청 흐름 추적 | 마이크로서비스 간 호출 체인, 병목 구간 |
이 세 가지를 합쳐서 MELT라고 부르기도 한다. (Metrics, Events, Logs, Traces)
Distributed Tracing 핵심 개념
분산 트레이싱을 이해하려면 Trace, Span, Trace ID의 개념을 먼저 알아야 한다.
Trace란?
Trace는 하나의 요청이 시스템을 통과하는 전체 여정이다. 마이크로서비스 환경에서 사용자의 한 번의 클릭이 여러 서비스를 거쳐 처리되는데, 이 전체 흐름을 하나의 Trace로 표현한다.
예를 들어 "주문 생성" 요청은 다음과 같은 경로를 거친다:
사용자 → API Gateway → Order Service → Inventory Service → Payment Service
이 전체 흐름이 하나의 Trace다.
Span이란?
Span은 Trace를 구성하는 개별 작업 단위다. 각 서비스에서 수행하는 작업, 데이터베이스 쿼리, 외부 API 호출 등이 각각 하나의 Span이 된다.
위 예시를 Span으로 나누면:
Trace: 주문 생성 요청
├── Span 1: API Gateway - 라우팅
├── Span 2: Order Service - 주문 검증
│ ├── Span 3: Order Service - 재고 확인 (Inventory Service 호출)
│ │ └── Span 4: Inventory Service - DB 조회
│ ├── Span 5: Order Service - 결제 처리 (Payment Service 호출)
│ │ └── Span 6: Payment Service - 외부 PG사 API 호출
│ └── Span 7: Order Service - 주문 저장 (DB INSERT)
└── Span 8: API Gateway - 응답 반환
각 Span은 다음 정보를 포함한다:
| 속성 | 설명 | 예시 |
|---|---|---|
| Span Name | 작업 이름 | GET /api/orders, DB Query, Kafka Publish |
| Start Time | 시작 시간 | 2026-01-25T15:30:45.123Z |
| Duration | 소요 시간 | 245ms |
| Status | 성공/실패 | OK, ERROR |
| Attributes | 추가 정보 (Key-Value) | http.status_code=200, db.statement=SELECT... |
| Events | 중요한 순간 기록 | cache.hit, retry.attempt |
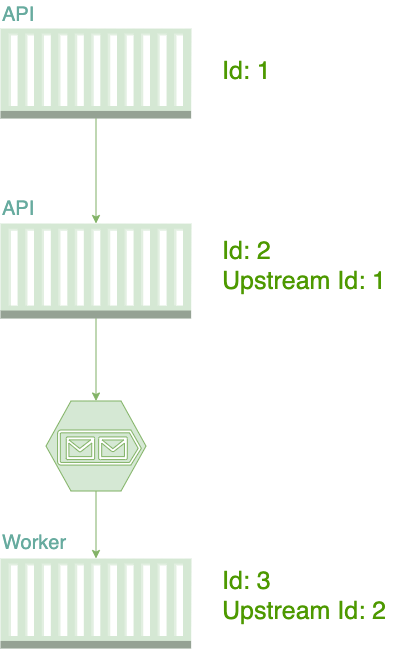
Trace ID와 Span ID
각 Trace와 Span은 고유한 ID를 가진다.
- Trace ID: 전체 요청을 식별하는 고유 ID (16바이트, 32자리 Hex)
- Span ID: 개별 Span을 식별하는 고유 ID (8바이트, 16자리 Hex)
- Parent Span ID: 상위 Span의 ID (계층 구조 표현)
예시:
Trace ID: 5f3a4b2c1d8e9f7a6b2c1d8e9f7a6b2c (모든 Span이 동일)
Span 1: API Gateway
- Span ID: abc123def4567890
- Parent Span ID: null (root span)
Span 2: Order Service
- Span ID: def456abc7890123
- Parent Span ID: abc123def4567890 (Span 1의 child)
Span 3: Inventory Service
- Span ID: ghi789def1234567
- Parent Span ID: def456abc7890123 (Span 2의 child)
W3C Trace Context
MSA 환경에서 하나의 Trace는 여러 서비스를 거치므로, Trace Context(Trace ID, Span ID 등)를 서비스 간에 전파해야 한다. 이때 W3C Trace Context 표준을 사용한다.
W3C Trace Context는 분산 시스템에서 trace context를 전파하기 위한 표준 HTTP 헤더와 값 형식을 정의한 공식 표준이다. 2020년 2월 W3C에서 공식 승인되었으며, OpenTelemetry를 포함한 대부분의 관측성 도구가 이 표준을 따른다.
왜 필요한가?
기존에는 각 벤더마다 다른 헤더 형식을 사용했다. Jaeger는 uber-trace-id, Zipkin은 X-B3-TraceId, Datadog은 x-datadog-trace-id 이런 식이었다. 서로 다른 도구를 사용하는 서비스 간에는 trace가 끊기는 문제가 발생했다.
W3C Trace Context는 모든 벤더가 동일한 헤더를 사용하도록 표준화했다. USB-C처럼 하나의 표준으로 모든 도구가 호환된다.
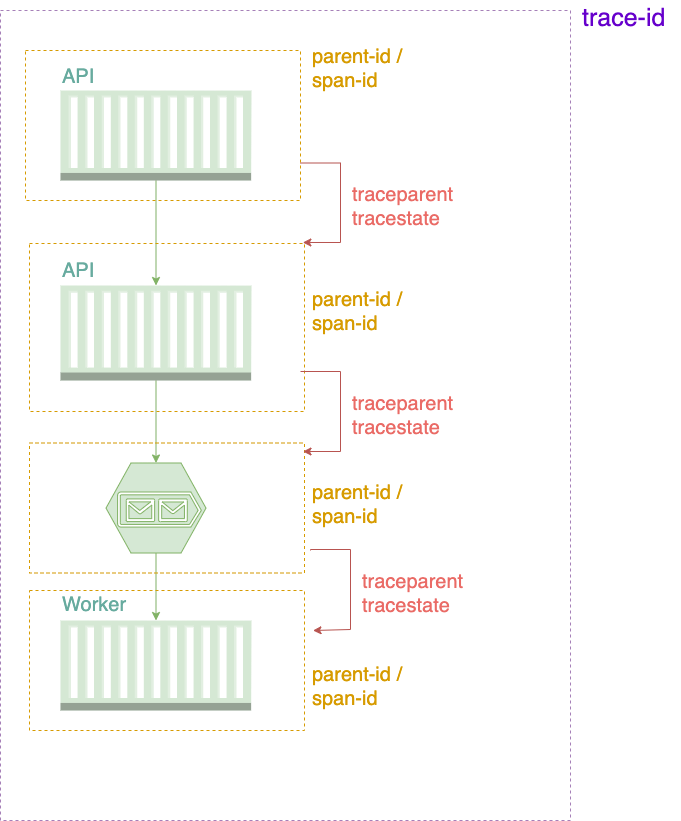
Traceparent 헤더
traceparent는 필수 헤더로, trace의 핵심 정보를 담는다.
형식:
traceparent: version-trace-id-parent-id-trace-flags
예시:
traceparent: 00-0af7651916cd43dd8448eb211c80319c-b7ad6b7169203331-01
각 필드 상세:
| 필드 | 크기 | 설명 | 예시 |
|---|---|---|---|
| version | 2자리 hex | 프로토콜 버전 (현재는 00만 사용) |
00 |
| trace-id | 32자리 hex | 전체 trace를 식별하는 16바이트 ID주의: 모두 0은 invalid | 0af7651916cd43dd8448eb211c80319c |
| parent-id | 16자리 hex | 현재 요청을 식별하는 8바이트 ID주의: 모두 0은 invalid | b7ad6b7169203331 |
| trace-flags | 2자리 hex | 8비트 플래그 (sampling, priority 등) | 01 |
trace-flags 상세:
trace-flags: 01 (2진수: 00000001)
│
└─ 비트 0: sampled flag
1 = 샘플링됨 (기록 대상)
0 = 샘플링 안됨
나머지 7비트는 미래 사용을 위해 예약 (모두 0이어야 함)
비트 플래그 확인 방법 (Java 예시):
boolean sampled = (traceFlags & 0x01) == 0x01;
HTTP 요청 예시:
GET /api/inventory/check HTTP/1.1
Host: inventory-service
traceparent: 00-0af7651916cd43dd8448eb211c80319c-b7ad6b7169203331-01
Tracestate 헤더 (선택사항)
tracestate는 선택적 헤더로, 벤더별 추가 정보를 담는다.
형식:
tracestate: key1=value1,key2=value2
예시:
tracestate: congo=t61rcWkgMzE,rojo=00f067aa0ba902b7
특징:
- 최대 32개 key-value 쌍 허용
- 최소 512자 이상 전파 권장
- 순서 중요: 왼쪽이 가장 최근 작업
- 키는 소문자 알파벳 +
_,-,*,/만 허용
사용 예시:
GET /api/payment HTTP/1.1
Host: payment-service
traceparent: 00-0af7651916cd43dd8448eb211c80319c-00f067aa0ba902b7-01
tracestate: payment=prioritize,congo=t61rcWkgMzE
서비스 간 전파 규칙
서비스가 다음 서비스로 요청을 보낼 때:
필수 변경:
- parent-id 업데이트: 새로운 Span ID로 변경
- trace-flags: 현재 서비스의 샘플링 결정 반영
유지:
- trace-id: 절대 변경하지 않음 (전체 trace 식별자)
- version: 그대로 유지
예시:
Service A 수신:
traceparent: 00-0af7651916cd43dd8448eb211c80319c-b7ad6b7169203331-01
Service A → Service B 전송:
traceparent: 00-0af7651916cd43dd8448eb211c80319c-00f067aa0ba902b7-01
│ │ │ │
│ └─ 동일한 trace-id │ │
│ └─ 새 parent-id │
└─ 동일한 version └─ 동일한 flags
수신하는 서비스는 이 헤더를 읽어서:
- 동일한 trace-id를 사용 (전체 trace 연결)
- 새로운 Span ID를 생성
- 받은 parent-id를 Parent Span ID로 설정
이렇게 해서 전체 호출 체인이 하나의 Trace로 연결된다.
메시지 브로커 전파
Kafka나 RabbitMQ를 사용할 때는 메시지 헤더를 통해 Trace Context를 전파한다.
{
"headers": {
"traceparent": "00-5f3a4b2c1d8e9f7a6b2c1d8e9f7a6b2c-def456abc7890123-01"
},
"payload": {
"orderId": "12345",
"userId": "user-001"
}
}
Consumer는 메시지를 받을 때 헤더에서 Trace Context를 추출하고, 새로운 Span을 생성한다.
Span의 종류
Span은 역할에 따라 종류가 나뉜다:
| Span Kind | 설명 | 예시 |
|---|---|---|
| SERVER | 서버가 요청을 받아 처리 | REST API 엔드포인트, gRPC 서버 |
| CLIENT | 클라이언트가 외부 서비스 호출 | HTTP Client, DB Client |
| PRODUCER | 메시지를 생성하여 전송 | Kafka Producer, RabbitMQ Publisher |
| CONSUMER | 메시지를 수신하여 처리 | Kafka Consumer, RabbitMQ Subscriber |
| INTERNAL | 내부 로직 처리 | 비즈니스 로직, 계산 작업 |
OpenTelemetry는 이 정보를 자동으로 설정해준다.
왜 Distributed Tracing이 필요한가?
모놀리식 애플리케이션에서는 로그와 디버거만으로도 문제를 찾을 수 있었다. 하지만 MSA 환경에서는:
- 하나의 요청이 5~10개 서비스를 거침
- 각 서비스는 다른 팀이 관리
- 어느 서비스에서 느려졌는지 찾기 어려움
문제 상황 예시:
증상: /api/orders 응답이 5초 걸림
로그만 보면:
- Order Service: "주문 생성 완료" (200ms)
- Inventory Service: "재고 확인 완료" (100ms)
- Payment Service: "결제 처리 완료" (4.5초) ← 여기가 범인!
하지만 로그만으로는 어느 호출이 느렸는지 찾기 어려움
Distributed Tracing으로 해결:
Tempo에서 Trace를 보면 한눈에 파악 가능:
Trace: GET /api/orders (총 5초)
├── Order Service - 주문 검증 (50ms)
├── Order Service → Inventory Service (100ms)
└── Order Service → Payment Service (4.5초) ← Waterfall 그래프로 바로 보임
└── Payment Service → PG사 API (4.3초) ← 실제 병목
이제 Payment Service의 외부 API 호출이 느리다는 걸 바로 알 수 있다.
OpenTelemetry란?
OpenTelemetry (줄여서 OTel)는 CNCF 프로젝트로, 관측성 데이터를 수집하고 전송하기 위한 표준이다. 기존에는 Prometheus는 Prometheus 형식, Jaeger는 Jaeger 형식 이런 식으로 각 벤더마다 형식이 달랐는데, OpenTelemetry로 하나로 통일되었다. USB-C처럼 모든 벤더가 쓸 수 있는 공통 규격이라고 보면 된다.
OpenTelemetry의 구성 요소
Application
↓ (Instrumentation)
OpenTelemetry SDK
↓ (OTLP Protocol)
OpenTelemetry Collector
↓ (Export)
Backend (Tempo, Mimir, Loki)
| 구성 요소 | 역할 |
|---|---|
| Instrumentation | 애플리케이션 코드에서 데이터를 수집 (Auto/Manual) |
| SDK | 수집한 데이터를 OTLP 형식으로 변환 |
| Collector | 데이터를 받아서 가공/필터링 후 백엔드로 전송 |
| OTLP | OpenTelemetry Protocol - 표준 전송 프로토콜 |
OTLP (OpenTelemetry Protocol)
OTLP는 OpenTelemetry의 표준 프로토콜이다. 버전 1.9.0부터 Logs, Metrics, Traces는 stable 상태고, Profiles는 현재 개발 중이다.
OTLP는 두 가지 인코딩 방식을 지원하는데, 실무에서는 거의 Protobuf를 쓴다.
| 인코딩 | 전송 방식 | 특징 |
|---|---|---|
| Protobuf | gRPC, HTTP | 바이너리 형식, 압축률 높음, 성능 우수 (권장) |
| JSON | HTTP | 텍스트 형식, 디버깅 용이, 레거시 호환 |
JSON은 디버깅할 때나 가끔 켜보는 정도다.
LGTM 스택이란?
LGTM 스택은 Grafana Labs에서 만든 오픈소스 관측성 플랫폼이다. LGTM은 Loki, Grafana, Tempo, Mimir의 앞 글자를 따온 약자다. 핵심 구성 요소는 다음과 같다.
| 구성 요소 | 역할 | 기존 대체 도구 |
|---|---|---|
| Grafana | 통합 대시보드 및 시각화 | Kibana, Jaeger UI |
| Tempo | 분산 트레이싱 백엔드 | Jaeger, Zipkin |
| Mimir | Prometheus Long-term Storage | Prometheus + Thanos/Cortex |
| Loki | 로그 수집 및 쿼리 | Elasticsearch |
Grafana Tempo
Tempo는 분산 트레이싱 전용 백엔드다. 기존 Jaeger와 비교했을 때 핵심 차이는 Object Storage만 필요하다는 점이다.
Jaeger는 Cassandra나 Elasticsearch를 백엔드로 써야 하는데, Tempo는 S3, GCS, MinIO 같은 Object Storage만 있으면 된다. 비용이 훨씬 저렴하다. Cassandra 클러스터 운영해본 사람은 알겠지만, DB 클러스터 운영 비용이 장난이 아니거든.
| 구분 | Jaeger | Tempo |
|---|---|---|
| 백엔드 스토리지 | Cassandra, Elasticsearch | Object Storage (S3, GCS, MinIO) |
| 쿼리 언어 | UI 검색 | TraceQL |
| 비용 | 높음 (DB 인프라) | 낮음 (Object Storage) |
| Grafana 통합 | 플러그인 필요 | 네이티브 지원 |
TraceQL 예시:
# HTTP 500 에러가 발생한 trace 검색
{ status = error && http.status_code = 500 }
# /api/orders 엔드포인트에서 1초 이상 걸린 trace
{ name = "GET /api/orders" && duration > 1s }
# 특정 서비스에서 발생한 DB 쿼리
{ service.name = "order-service" && db.system = "postgresql" }
Grafana Mimir
Mimir는 Prometheus의 장기 저장소(Long-term Storage) 역할을 한다. Prometheus는 기본적으로 로컬 디스크에 메트릭을 저장하는데, 용량 제한이 있고 고가용성을 보장하기 어렵다.
Mimir는 다음과 같은 문제를 해결한다.
- Prometheus의 메트릭을 Object Storage에 저장 (무제한 확장)
- 10억 개 이상의 active series 처리 가능
- Multi-tenancy 지원 (여러 팀이 하나의 Mimir 사용)
- PromQL로 장기간 데이터 쿼리
동작 방식:
Prometheus (Scraper)
↓ remote_write
Mimir Distributor
↓
Mimir Ingester (메모리 버퍼)
↓ 주기적 flush
Object Storage (S3, GCS)
↓ 쿼리 시
Mimir Querier → Grafana
Prometheus는 계속 메트릭을 수집하지만, remote_write 설정으로 Mimir에 전송한다. Mimir는 이를 받아서 Object Storage에 저장하고, Grafana에서 PromQL로 조회할 수 있다.
Grafana Loki
Loki는 Prometheus의 철학을 로그 시스템에 적용한 거라고 보면 된다. Elasticsearch와 다르게 로그 내용을 인덱싱하지 않고 레이블만 인덱싱한다.
| 구분 | Elasticsearch | Loki |
|---|---|---|
| 인덱싱 | 전문 검색 (Full-text) | 레이블만 인덱싱 |
| 저장소 | 자체 스토리지 | Object Storage |
| 쿼리 언어 | Lucene Query | LogQL (PromQL과 유사) |
| 비용 | 높음 (인덱싱 비용) | 낮음 |
Loki는 로그를 레이블로만 검색한다. 예를 들어 {service="order-service", level="error"} 이런 식이다. 로그 내용을 grep처럼 검색하려면 LogQL 필터를 사용한다.
"레이블만 인덱싱하면 로그 내용 검색이 느리지 않나요?"
맞다. Loki의 |= "HTTP 500" 필터는 인덱스를 타지 않고 로그 파일을 직접 읽는다. 대신 레이블로 먼저 범위를 좁히기 때문에 생각보다 빠르다. {service="api-gateway", level="error"} |= "HTTP 500" 이런 식으로 레이블 필터를 먼저 걸면, 전체 로그가 아니라 해당 서비스의 error 로그만 스캔한다.
수억 건 로그에서 전문 검색이 필요하면 Elasticsearch가 낫지만, 대부분의 경우 레이블 + 간단한 필터로 충분하다. Loki의 장점은 비용이다. Elasticsearch는 인덱싱 비용이 스토리지의 2~3배인데, Loki는 거의 스토리지 비용만 든다.
LogQL 예시:
# order-service의 error 로그
{service="order-service", level="error"}
# HTTP 500 에러가 포함된 로그
{service="api-gateway"} |= "HTTP 500"
# JSON 로그에서 status_code가 500인 경우
{service="api-gateway"} | json | status_code = "500"
# 분당 에러 발생 건수
sum(rate({level="error"}[1m]))
Spring Boot 애플리케이션에 OpenTelemetry 적용
Spring Boot에서 OpenTelemetry를 적용하는 방법은 크게 두 가지가 있다. Java Agent 방식이 가장 간단하지만, Spring Boot 3.x/4.x에서는 Micrometer Tracing을 통한 네이티브 통합도 가능하다.
1. Java Agent 방식 (Zero Code Change)
가장 간단한 방법이다. 코드 변경 없이 JAR 파일 하나 다운로드해서 -javaagent 옵션만 붙이면 끝이다.
# OpenTelemetry Java Agent 다운로드
wget https://github.com/open-telemetry/opentelemetry-java-instrumentation/releases/latest/download/opentelemetry-javaagent.jar
# Spring Boot 애플리케이션 실행
java -javaagent:opentelemetry-javaagent.jar \
-Dotel.service.name=order-service \
-Dotel.traces.exporter=otlp \
-Dotel.metrics.exporter=otlp \
-Dotel.logs.exporter=otlp \
-Dotel.exporter.otlp.endpoint=http://localhost:4317 \
-jar target/order-service.jar
이렇게 실행하면 Spring MVC, JDBC, HTTP Client 등의 라이브러리가 자동으로 계측(instrumentation)된다. Zero Code Change로 Traces, Metrics, Logs가 수집된다. 마법 같은데 실제로 동작한다.
자동 계측되는 라이브러리:
- Spring MVC / WebFlux (HTTP 요청/응답)
- JDBC / R2DBC (데이터베이스 쿼리)
- RestTemplate / WebClient (HTTP 클라이언트)
- Kafka / RabbitMQ (메시지 브로커)
- Redis / MongoDB (NoSQL)
2. Spring Boot Starter 방식 (Spring Boot 3.x/4.x)
Spring Boot 3.x (Micrometer Tracing)
Spring Boot 3.x에서는 Micrometer Tracing을 통해 OpenTelemetry를 통합한다. Micrometer는 Spring Boot의 표준 Observability API로, Actuator와 함께 사용된다.
<!-- pom.xml -->
<dependencies>
<!-- Spring Boot Actuator -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!-- Micrometer Tracing with OpenTelemetry -->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-tracing-bridge-otel</artifactId>
</dependency>
<!-- OpenTelemetry OTLP Exporter -->
<dependency>
<groupId>io.opentelemetry</groupId>
<artifactId>opentelemetry-exporter-otlp</artifactId>
</dependency>
</dependencies>
# application.yml
spring:
application:
name: order-service
management:
# Actuator endpoints 활성화
endpoints:
web:
exposure:
include: health,info,metrics,prometheus
# Tracing 설정
tracing:
sampling:
probability: 1.0 # 100% 샘플링 (개발 환경용)
# OTLP Exporter 설정
otlp:
tracing:
endpoint: http://localhost:4318/v1/traces # HTTP endpoint
metrics:
export:
url: http://localhost:4318/v1/metrics
# Metrics 설정
metrics:
tags:
application: ${spring.application.name} # 모든 메트릭에 application tag 추가
environment: dev
Spring Boot 4.0 (신규 OpenTelemetry Starter)
Spring Boot 4.0부터는 spring-boot-starter-opentelemetry가 추가되어 더 간단해졌다.
<!-- pom.xml -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-opentelemetry</artifactId>
</dependency>
# application.yml
spring:
application:
name: order-service
otel:
service:
name: ${spring.application.name}
exporter:
otlp:
endpoint: http://localhost:4317
traces:
sampler: always_on # 개발 환경용
어떤 방식을 써야 하나?
| 상황 | 권장 방식 |
|---|---|
| 일반적인 Spring Boot 애플리케이션 | Java Agent (더 많은 자동 계측) |
| Spring Boot 4.0+ 프로젝트 | Spring Boot Starter (spring-boot-starter-opentelemetry) |
| Spring Boot 3.x 프로젝트 | Micrometer Tracing + OpenTelemetry |
| Spring Boot Native Image 사용 | Spring Boot Starter |
| 설정을 application.yml로 관리하고 싶음 | Spring Boot Starter |
| 컨테이너 이미지 크기가 중요함 | Spring Boot Starter |
로그에 Trace ID / Span ID 출력하기
OpenTelemetry를 통합하면 MDC(Mapped Diagnostic Context)에 자동으로 trace_id와 span_id가 추가된다. Logback 설정을 수정해서 로그에 포함시킬 수 있다.
<!-- src/main/resources/logback-spring.xml -->
<configuration>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>
%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - [traceId=%X{traceId:-}, spanId=%X{spanId:-}] - %msg%n
</pattern>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE"/>
</root>
</configuration>
JSON 로그 형식 (프로덕션 권장):
<!-- Logback Logstash Encoder 사용 -->
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>7.4</version>
</dependency>
<configuration>
<appender name="JSON" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="net.logstash.logback.encoder.LogstashEncoder">
<includeMdcKeyName>traceId</includeMdcKeyName>
<includeMdcKeyName>spanId</includeMdcKeyName>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="JSON"/>
</root>
</configuration>
JSON 출력 예시:
{
"@timestamp": "2026-01-25T15:30:45.123Z",
"level": "INFO",
"logger_name": "com.example.OrderController",
"message": "Creating order for user: 12345",
"traceId": "5f3a4b2c1d8e9f7a",
"spanId": "3c9d1e4f"
}
Metrics에 Tag (Label) 추가하기
Micrometer를 사용하면 메트릭에 Tag를 추가할 수 있다. Tag는 Prometheus의 Label과 동일한 개념이다.
1. 글로벌 Tag 추가
모든 메트릭에 공통으로 추가되는 Tag는 application.yml에서 설정한다.
# application.yml
management:
metrics:
tags:
application: ${spring.application.name}
environment: ${ENVIRONMENT:dev}
region: ${AWS_REGION:ap-northeast-2}
instance: ${HOSTNAME:localhost}
2. @Timed, @Counted 어노테이션으로 Tag 추가
Spring Boot에서 메트릭 어노테이션을 활성화해야 한다.
# application.yml
management:
observations:
annotations:
enabled: true # @Timed, @Counted, @NewSpan 활성화
import io.micrometer.core.annotation.Timed;
import io.micrometer.core.annotation.Counted;
import io.micrometer.observation.annotation.Observed;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/api/orders")
public class OrderController {
private final OrderService orderService;
public OrderController(OrderService orderService) {
this.orderService = orderService;
}
@PostMapping
@Timed(value = "orders.create", description = "주문 생성 시간", extraTags = {"type", "online"})
@Counted(value = "orders.created", description = "주문 생성 건수")
public Order createOrder(@RequestBody CreateOrderRequest request) {
return orderService.create(request);
}
@GetMapping("/{id}")
@Timed(value = "orders.get", extraTags = {"type", "query"})
public Order getOrder(@PathVariable Long id) {
return orderService.findById(id);
}
}
3. MeterRegistry로 동적 Tag 추가
비즈니스 로직에서 동적으로 Tag를 추가할 수 있다.
import io.micrometer.core.instrument.Counter;
import io.micrometer.core.instrument.MeterRegistry;
import io.micrometer.core.instrument.Timer;
import org.springframework.stereotype.Service;
@Service
public class OrderService {
private final MeterRegistry meterRegistry;
private final OrderRepository orderRepository;
public OrderService(MeterRegistry meterRegistry, OrderRepository orderRepository) {
this.meterRegistry = meterRegistry;
this.orderRepository = orderRepository;
}
public Order create(CreateOrderRequest request) {
Timer.Sample sample = Timer.start(meterRegistry);
try {
Order order = orderRepository.save(new Order(request));
// 성공 시 메트릭 기록
Counter.builder("orders.created")
.tag("status", "success")
.tag("payment_method", request.getPaymentMethod())
.tag("user_tier", getUserTier(request.getUserId())) // 동적 tag
.register(meterRegistry)
.increment();
sample.stop(Timer.builder("orders.creation.time")
.tag("status", "success")
.register(meterRegistry));
return order;
} catch (Exception e) {
// 실패 시 메트릭 기록
Counter.builder("orders.created")
.tag("status", "failed")
.tag("error_type", e.getClass().getSimpleName())
.register(meterRegistry)
.increment();
sample.stop(Timer.builder("orders.creation.time")
.tag("status", "failed")
.register(meterRegistry));
throw e;
}
}
private String getUserTier(String userId) {
// 비즈니스 로직으로 사용자 등급 조회
return "gold"; // 예시
}
}
주의: Cardinality 폭발 방지
// 잘못된 예: user_id를 tag로 추가 (Cardinality 폭발)
Counter.builder("orders.created")
.tag("user_id", userId) // 수백만 개의 series 생성
.register(meterRegistry);
// 올바른 예: user_tier처럼 제한된 값만 tag로 사용
Counter.builder("orders.created")
.tag("user_tier", getUserTier(userId)) // "gold", "silver", "bronze" 3가지만
.register(meterRegistry);
MSA 환경에서 Span 전파 및 관리
MSA 환경에서는 하나의 요청이 여러 서비스를 거치므로, Trace Context를 전파하는 것이 중요하다. OpenTelemetry는 W3C Trace Context 표준을 사용한다.
1. HTTP 요청 간 Span 자동 전파
Spring Boot + OpenTelemetry를 사용하면 RestTemplate, WebClient, Feign Client에서 자동으로 Trace Context가 전파된다.
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.client.RestTemplate;
import org.springframework.web.reactive.function.client.WebClient;
@Configuration
public class HttpClientConfig {
// RestTemplate - 자동으로 Trace Context 전파
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
// WebClient - 자동으로 Trace Context 전파
@Bean
public WebClient webClient() {
return WebClient.builder()
.baseUrl("http://inventory-service")
.build();
}
}
@Service
public class OrderService {
private final RestTemplate restTemplate;
private final WebClient webClient;
public OrderService(RestTemplate restTemplate, WebClient webClient) {
this.restTemplate = restTemplate;
this.webClient = webClient;
}
public Order createOrder(CreateOrderRequest request) {
// RestTemplate 사용 - Trace Context 자동 전파
InventoryResponse inventory = restTemplate.getForObject(
"http://inventory-service/api/inventory/check",
InventoryResponse.class
);
// WebClient 사용 - Trace Context 자동 전파 (Reactive)
PaymentResponse payment = webClient.post()
.uri("/api/payment/process")
.bodyValue(request)
.retrieve()
.bodyToMono(PaymentResponse.class)
.block();
return new Order(request, inventory, payment);
}
}
전파되는 HTTP 헤더:
traceparent: W3C Trace Context 표준 헤더 (trace_id, span_id 포함)tracestate: 추가 벤더 정보 (선택적)
GET /api/inventory/check HTTP/1.1
Host: inventory-service
traceparent: 00-5f3a4b2c1d8e9f7a6b2c1d8e9f7a6b2c-3c9d1e4f2a1b3c4d-01
2. 메시지 브로커(Kafka, RabbitMQ)에서 Span 전파
Kafka나 RabbitMQ를 사용하는 경우, Message Header를 통해 Trace Context가 전파된다.
Kafka 예시:
import io.opentelemetry.api.trace.Span;
import io.opentelemetry.api.trace.Tracer;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.Message;
import org.springframework.messaging.support.MessageBuilder;
import org.springframework.stereotype.Service;
@Service
public class OrderEventPublisher {
private final KafkaTemplate<String, OrderEvent> kafkaTemplate;
private final Tracer tracer;
public OrderEventPublisher(KafkaTemplate<String, OrderEvent> kafkaTemplate, Tracer tracer) {
this.kafkaTemplate = kafkaTemplate;
this.tracer = tracer;
}
public void publishOrderCreated(Order order) {
// Span 생성 (선택적 - 추가 정보 기록용)
Span span = tracer.spanBuilder("kafka.publish.order-created")
.setAttribute("order.id", order.getId())
.setAttribute("kafka.topic", "order-events")
.startSpan();
try {
OrderEvent event = new OrderEvent(order);
// Kafka Message 전송 - Trace Context 자동 포함
Message<OrderEvent> message = MessageBuilder
.withPayload(event)
.setHeader(KafkaHeaders.TOPIC, "order-events")
.setHeader(KafkaHeaders.KEY, order.getId().toString())
.build();
kafkaTemplate.send(message);
span.addEvent("order.event.published");
} finally {
span.end();
}
}
}
Kafka Consumer에서 Trace Context 수신:
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.messaging.handler.annotation.Payload;
import org.springframework.stereotype.Service;
@Service
public class InventoryEventConsumer {
private final InventoryService inventoryService;
public InventoryEventConsumer(InventoryService inventoryService) {
this.inventoryService = inventoryService;
}
@KafkaListener(topics = "order-events", groupId = "inventory-service")
public void handleOrderCreated(@Payload OrderEvent event) {
// Trace Context가 자동으로 복원됨
// 현재 Span의 parent는 Producer의 Span이 됨
inventoryService.reserveStock(event.getOrderId(), event.getItems());
}
}
OpenTelemetry Java Agent나 Micrometer Tracing을 사용하면 Kafka Producer/Consumer의 Trace Context 전파가 자동으로 처리된다.
3. Custom Span 생성 및 Attribute 추가
비즈니스 로직의 특정 구간을 추적하고 싶을 때는 Custom Span을 만든다.
import io.opentelemetry.api.trace.Span;
import io.opentelemetry.api.trace.StatusCode;
import io.opentelemetry.api.trace.Tracer;
import io.opentelemetry.context.Scope;
import org.springframework.stereotype.Service;
@Service
public class OrderService {
private final Tracer tracer;
private final InventoryClient inventoryClient;
private final PaymentClient paymentClient;
public OrderService(Tracer tracer, InventoryClient inventoryClient, PaymentClient paymentClient) {
this.tracer = tracer;
this.inventoryClient = inventoryClient;
this.paymentClient = paymentClient;
}
public Order createOrder(CreateOrderRequest request) {
// Custom Span 시작
Span span = tracer.spanBuilder("OrderService.createOrder")
.setAttribute("user.id", request.getUserId())
.setAttribute("order.items.count", request.getItems().size())
.setAttribute("order.total.amount", request.getTotalAmount())
.startSpan();
try (Scope scope = span.makeCurrent()) {
// Step 1: 재고 확인
Span inventorySpan = tracer.spanBuilder("checkInventory").startSpan();
try (Scope inventoryScope = inventorySpan.makeCurrent()) {
inventoryClient.checkStock(request.getItems());
inventorySpan.addEvent("inventory.checked");
} finally {
inventorySpan.end();
}
// Step 2: 결제 처리
Span paymentSpan = tracer.spanBuilder("processPayment").startSpan();
try (Scope paymentScope = paymentSpan.makeCurrent()) {
paymentClient.process(request.getPayment());
paymentSpan.addEvent("payment.processed");
} finally {
paymentSpan.end();
}
// Step 3: 주문 저장
Order order = orderRepository.save(new Order(request));
span.setAttribute("order.id", order.getId());
span.addEvent("order.saved");
return order;
} catch (InsufficientStockException e) {
span.recordException(e);
span.setStatus(StatusCode.ERROR, "재고 부족");
throw e;
} catch (PaymentFailedException e) {
span.recordException(e);
span.setStatus(StatusCode.ERROR, "결제 실패");
throw e;
} finally {
span.end();
}
}
}
Span Hierarchy:
OrderService.createOrder (parent)
├── checkInventory (child)
├── processPayment (child)
└── InventoryClient.checkStock (auto-instrumented, child)
4. 분산 트레이싱 전파 흐름
MSA 환경에서 하나의 요청이 여러 서비스를 거칠 때의 Span 전파:
User Request → API Gateway → Order Service → Inventory Service
→ Payment Service
Trace ID: 5f3a4b2c1d8e9f7a (모든 서비스에서 동일)
Spans:
├── [API Gateway] GET /api/orders (Span ID: abc123, Parent: null)
└── [Order Service] OrderService.createOrder (Span ID: def456, Parent: abc123)
├── [Order Service] checkInventory (Span ID: ghi789, Parent: def456)
│ └── [Inventory Service] GET /api/inventory (Span ID: jkl012, Parent: ghi789)
└── [Order Service] processPayment (Span ID: mno345, Parent: def456)
└── [Payment Service] POST /api/payment (Span ID: pqr678, Parent: mno345)
모든 Span은 동일한 Trace ID를 공유하고, Tempo에서 전체 흐름을 하나의 Trace로 시각화할 수 있다.
OpenTelemetry Collector 설정
OpenTelemetry Collector는 일종의 우체국 허브 같은 역할을 한다. 애플리케이션에서 보낸 데이터를 받아서 정리하고, 적절한 백엔드로 배송한다. 필수는 아니지만 실무에서는 거의 항상 쓴다.
Collector를 쓰는 이유:
- 애플리케이션 코드와 백엔드를 분리 (백엔드가 바뀌어도 애플리케이션 재배포 불필요)
- 데이터 필터링, 샘플링, 배치 처리로 백엔드 부하 감소
- 여러 백엔드로 동시 전송 (Tempo + Jaeger 동시 사용 등)
Collector의 성능 오버헤드는?
Collector 자체는 매우 가볍다. CPU 1코어, 메모리 512MB 정도면 초당 수만 건의 Span을 처리할 수 있다. 오히려 애플리케이션에서 직접 백엔드로 전송하는 것보다 Collector를 거치는 게 더 효율적이다. Collector가 배치 처리를 해서 네트워크 요청 횟수를 줄여주기 때문이다.
# otel-collector-config.yaml
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
processors:
batch:
timeout: 10s
send_batch_size: 1024
# 메모리 제한
memory_limiter:
check_interval: 1s
limit_mib: 512
exporters:
# Tempo로 Traces 전송
otlp/tempo:
endpoint: tempo:4317
tls:
insecure: true
# Mimir로 Metrics 전송 (Prometheus remote_write)
prometheusremotewrite:
endpoint: http://mimir:9009/api/v1/push
# Loki로 Logs 전송
loki:
endpoint: http://loki:3100/loki/api/v1/push
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch, memory_limiter]
exporters: [otlp/tempo]
metrics:
receivers: [otlp]
processors: [batch, memory_limiter]
exporters: [prometheusremotewrite]
logs:
receivers: [otlp]
processors: [batch, memory_limiter]
exporters: [loki]
Collector 실행
# Docker로 실행
docker run -d --name otel-collector \
-p 4317:4317 -p 4318:4318 \
-v $(pwd)/otel-collector-config.yaml:/etc/otel-collector-config.yaml \
otel/opentelemetry-collector:latest \
--config=/etc/otel-collector-config.yaml
Docker Compose로 전체 스택 실행
실습을 위한 전체 스택을 Docker Compose로 구성하면 다음과 같다.
# docker-compose.yml
services:
# OpenTelemetry Collector
otel-collector:
image: otel/opentelemetry-collector:latest
command: ["--config=/etc/otel-collector-config.yaml"]
volumes:
- ./otel-collector-config.yaml:/etc/otel-collector-config.yaml
ports:
- "4317:4317" # OTLP gRPC
- "4318:4318" # OTLP HTTP
# Tempo (분산 트레이싱)
tempo:
image: grafana/tempo:latest
command: ["-config.file=/etc/tempo.yaml"]
volumes:
- ./tempo-config.yaml:/etc/tempo.yaml
- tempo-data:/var/tempo
ports:
- "3200:3200" # Tempo HTTP
- "4317" # OTLP gRPC receiver
# Mimir (Metrics Long-term Storage)
mimir:
image: grafana/mimir:latest
command: ["-config.file=/etc/mimir.yaml"]
volumes:
- ./mimir-config.yaml:/etc/mimir.yaml
- mimir-data:/data
ports:
- "9009:9009" # HTTP
# Loki (로그 수집)
loki:
image: grafana/loki:latest
command: ["-config.file=/etc/loki/local-config.yaml"]
ports:
- "3100:3100"
volumes:
- loki-data:/loki
# Grafana (시각화)
grafana:
image: grafana/grafana:latest
ports:
- "3000:3000"
environment:
- GF_AUTH_ANONYMOUS_ENABLED=true
- GF_AUTH_ANONYMOUS_ORG_ROLE=Admin
volumes:
- grafana-data:/var/lib/grafana
- ./grafana-datasources.yaml:/etc/grafana/provisioning/datasources/datasources.yaml
volumes:
tempo-data:
mimir-data:
loki-data:
grafana-data:
Tempo 설정
로컬 개발 환경에서는 backend: local로 파일 시스템을 사용하지만, 프로덕션에서는 S3/GCS를 써야 한다.
# tempo-config.yaml (로컬 개발용)
server:
http_listen_port: 3200
distributor:
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
storage:
trace:
backend: local
local:
path: /var/tempo/traces
query_frontend:
search:
enabled: true
프로덕션 S3 설정 예시:
# tempo-config.yaml (프로덕션용 - S3)
storage:
trace:
backend: s3
s3:
bucket: my-tempo-traces
endpoint: s3.ap-northeast-2.amazonaws.com
pool:
max_workers: 100
queue_depth: 10000
Mimir 설정 (단일 노드)
# mimir-config.yaml
target: all
multitenancy_enabled: false
server:
http_listen_port: 9009
common:
storage:
backend: filesystem
filesystem:
dir: /data/mimir
blocks_storage:
filesystem:
dir: /data/mimir/blocks
ruler_storage:
filesystem:
dir: /data/mimir/rules
Grafana 데이터소스 설정
# grafana-datasources.yaml
apiVersion: 1
datasources:
# Tempo (Traces)
- name: Tempo
type: tempo
access: proxy
url: http://tempo:3200
uid: tempo
# Mimir (Metrics)
- name: Mimir
type: prometheus
access: proxy
url: http://mimir:9009/prometheus
uid: mimir
# Loki (Logs)
- name: Loki
type: loki
access: proxy
url: http://loki:3100
uid: loki
Grafana에서 Traces, Metrics, Logs 연결하기
Grafana에서 세 가지 신호를 연결하는 방법은 Trace ID를 기준으로 한다.
1. Trace에서 Logs로 이동
Tempo에서 Trace를 보다가 특정 Span을 클릭하면 해당 시점의 로그를 Loki에서 자동으로 조회할 수 있다. 이를 위해 다음 설정이 필요하다.
Grafana 데이터소스 설정 (UI):
- Tempo 데이터소스 설정으로 이동
- "Trace to logs" 섹션에서 Loki 데이터소스 선택
- Tag 매핑 설정:
service.name→servicetrace_id→trace_id
이렇게 설정하면 Trace를 클릭했을 때 자동으로 다음 LogQL 쿼리가 실행된다.
{service="order-service"} |= "trace_id=<현재 trace_id>"
2. Logs에서 Trace로 이동
로그에 Trace ID를 포함하면 Loki에서 로그를 보다가 바로 Tempo로 점프할 수 있다.
Spring Boot 로그 설정 (logback.xml):
<configuration>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} trace_id=%X{trace_id} span_id=%X{span_id} - %msg%n</pattern>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE"/>
</root>
</configuration>
OpenTelemetry Java Agent를 사용하면 trace_id와 span_id가 자동으로 MDC에 추가된다.
3. Metrics에서 Trace로 이동
Prometheus 메트릭에 Exemplar를 추가하면 메트릭 그래프에서 특정 데이터 포인트를 클릭했을 때 해당 Trace로 이동할 수 있다.
// Micrometer + OpenTelemetry 통합 시 자동으로 Exemplar 추가됨
@RestController
public class OrderController {
private final Counter orderCounter;
public OrderController(MeterRegistry registry) {
this.orderCounter = Counter.builder("orders.created")
.tag("status", "success")
.register(registry);
}
@PostMapping("/orders")
public Order createOrder(@RequestBody CreateOrderRequest request) {
Order order = orderService.create(request);
orderCounter.increment(); // Trace ID가 Exemplar로 자동 추가됨
return order;
}
}
Grafana에서 메트릭 그래프를 보면 데이터 포인트에 파란색 점이 표시되는데, 클릭하면 해당 Trace로 바로 이동한다.
Custom Span과 Manual Instrumentation
자동 계측만으로 부족하면 수동으로 Span을 추가할 수 있다.
import io.opentelemetry.api.trace.Span;
import io.opentelemetry.api.trace.StatusCode;
import io.opentelemetry.api.trace.Tracer;
import io.opentelemetry.context.Scope;
import org.springframework.stereotype.Service;
@Service
public class OrderService {
private final Tracer tracer;
private final InventoryClient inventoryClient;
public OrderService(Tracer tracer, InventoryClient inventoryClient) {
this.tracer = tracer;
this.inventoryClient = inventoryClient;
}
public Order createOrder(CreateOrderRequest request) {
// Custom Span 생성
Span span = tracer.spanBuilder("createOrder")
.setAttribute("user.id", request.getUserId())
.setAttribute("order.items", request.getItems().size())
.startSpan();
try (Scope scope = span.makeCurrent()) {
// 비즈니스 로직
Order order = new Order(request.getUserId(), request.getItems());
// 재고 확인 (자동 계측됨)
inventoryClient.checkStock(request.getItems());
// 중요한 이벤트 기록
span.addEvent("order.validated");
orderRepository.save(order);
span.addEvent("order.saved");
return order;
} catch (Exception e) {
// 에러 기록
span.recordException(e);
span.setStatus(StatusCode.ERROR, e.getMessage());
throw e;
} finally {
span.end();
}
}
}
Span에 추가한 Attribute는 Tempo에서 TraceQL로 검색할 수 있다.
# user.id가 123인 주문 trace 검색
{ span.user.id = "123" }
# 3개 이상 상품을 주문한 trace
{ span.order.items >= 3 }
실무 운영 시 주의사항
1. 샘플링 설정
프로덕션 환경에서 모든 Trace를 수집하면 비용이 급증한다. 100% 샘플링은 개발 환경에서만 쓰고, 프로덕션에서는 10% 정도로 낮춰야 한다.
# application.yml
management:
tracing:
sampling:
probability: 0.1 # 10%만 샘플링
Tail Sampling (OpenTelemetry Collector 레벨):
에러가 발생한 Trace만 100% 수집하고, 정상 Trace는 10%만 수집하는 방식이다. CCTV 녹화처럼, 일단 전부 받아놓고 나중에 중요한 것만 저장하는 거라고 보면 된다.
Tail Sampling은 Trace가 완료될 때까지 기다렸다가 판단하므로, Collector 메모리에 Trace를 일시 보관한다. 메모리가 부족하면 오래된 Trace부터 버려지므로, memory_limiter processor로 메모리 사용량을 제한하는 게 중요하다.
# otel-collector-config.yaml
processors:
tail_sampling:
policies:
- name: errors-policy
type: status_code
status_code:
status_codes: [ERROR]
- name: slow-requests
type: latency
latency:
threshold_ms: 1000
- name: probabilistic-policy
type: probabilistic
probabilistic:
sampling_percentage: 10
service:
pipelines:
traces:
processors: [tail_sampling, batch, memory_limiter]
2. Cardinality 폭발 방지
Cardinality는 메트릭의 고유한 조합 개수를 의미한다. 예를 들어 http_requests_total{method="GET", endpoint="/api/users"}라는 메트릭이 있으면, method 값 종류 × endpoint 값 종류가 Cardinality다.
Metrics에서 tag 값이 무한히 증가하면 Mimir가 죽는다. 예를 들어 User ID를 tag로 추가하면 사용자 100만 명 = Cardinality 100만이 되어 메모리가 폭발한다.
안전한 Cardinality 기준:
- 단일 메트릭: ~1,000 이하
- 전체 시스템: ~100만 series 이하 (소규모), ~1,000만 이하 (중규모)
Grafana에서 sum(count({__name__=~".+"})) by (__name__) 쿼리로 메트릭별 series 수를 모니터링할 수 있다.
// 잘못된 예: user_id를 tag로 추가 (Cardinality 폭발)
Counter.builder("user.requests")
.tag("user_id", userId) // 수백만 개의 user_id가 tag가 됨
.register(registry);
// 올바른 예: user_id는 로그나 Trace에만 기록
Counter.builder("user.requests")
.tag("endpoint", "/api/users")
.register(registry);
// Trace에서는 user_id를 Attribute로 추가 (문제없음)
span.setAttribute("user.id", userId);
3. 민감 정보 필터링
Trace나 로그에 개인정보가 포함되지 않도록 필터링해야 한다.
# otel-collector-config.yaml
processors:
attributes:
actions:
# HTTP 헤더에서 Authorization 제거
- key: http.request.header.authorization
action: delete
# 쿼리 파라미터에서 password 제거
- key: http.url
pattern: password=[^&]*
action: delete
4. Tempo 데이터 보관 주기
Tempo는 기본적으로 모든 Trace를 영구 보관한다. 비용 절감을 위해 보관 주기를 설정하는 게 좋다.
# tempo-config.yaml
compactor:
compaction:
block_retention: 336h # 14일 보관
5. Mimir 용량 계획
Mimir는 메트릭 데이터를 Object Storage에 저장하므로 용량 제한은 없지만, Ingester 메모리와 Querier 성능을 고려해야 한다.
| 메트릭 수 | Ingester 메모리 | Querier 메모리 |
|---|---|---|
| ~100만 series | 2GB | 4GB |
| ~1000만 series | 8GB | 16GB |
| ~1억 series | 32GB | 64GB |
자주 묻는 질문 (FAQ)
Q1: 기존에 Prometheus + Grafana를 쓰는데 Mimir로 마이그레이션하려면?
Prometheus는 그대로 두고 remote_write 설정만 추가하면 된다. 기존 데이터는 Prometheus에 남아있고, 새 데이터부터 Mimir로 전송된다.
# prometheus.yml
remote_write:
- url: http://mimir:9009/api/v1/push
queue_config:
capacity: 10000
max_shards: 50
기존 데이터를 Mimir로 옮기려면 Prometheus의 snapshot 기능을 사용하거나, promtool로 백필할 수 있다.
Q2: Micrometer Tracing에서 OpenTelemetry로 바꾸려면 코드 수정이 많나?
Spring Boot 3.x에서 Micrometer Tracing을 쓰고 있다면, OpenTelemetry는 이미 통합되어 있다. micrometer-tracing-bridge-otel 의존성만 추가하면 자동으로 OpenTelemetry로 전환된다. 코드 수정은 거의 없다.
단, Custom Span을 직접 만들었다면 Micrometer API → OpenTelemetry API로 바꿔야 한다.
Q3: Kubernetes에서 Collector를 Sidecar vs DaemonSet?
Kubernetes에서 OpenTelemetry Collector를 배포하는 방식은 크게 두 가지다. 각각의 구조와 장단점을 비교해보자.
1. Sidecar 패턴
구조: 각 애플리케이션 Pod마다 Collector 컨테이너가 같이 배포된다.
Node 1
├── Pod: order-service-1
│ ├── Container: order-service (애플리케이션)
│ └── Container: otel-collector (전용 Collector)
│
├── Pod: order-service-2
│ ├── Container: order-service (애플리케이션)
│ └── Container: otel-collector (전용 Collector)
│
└── Pod: payment-service-1
├── Container: payment-service (애플리케이션)
└── Container: otel-collector (전용 Collector)
Node 2
├── Pod: inventory-service-1
│ ├── Container: inventory-service (애플리케이션)
│ └── Container: otel-collector (전용 Collector)
데이터 흐름:
애플리케이션 → localhost:4317 (같은 Pod의 Collector) → Gateway Collector → Backend
장점:
- Pod별 격리: 각 Pod이 독립적인 Collector를 가짐
- 설정 유연성: 팀/서비스별로 다른 Collector 설정 가능
- 네트워크 홉 최소화: Pod 내부 통신 (localhost)
- 높은 충실도: Pod 컨텍스트(namespace, pod name 등) 자동 추가
- AWS Fargate, GCP Cloud Run 지원: Node 접근이 불가능한 서버리스 환경에서 유일한 선택
단점:
- 리소스 중복: Pod 100개 = Collector 100개 (메모리/CPU 낭비)
- 관리 복잡도: Collector 설정 변경 시 모든 Pod 재시작 필요
- 버전 불일치: 각 팀이 다른 Collector 버전 사용 가능
리소스 사용량 예시:
Pod 100개, Collector당 메모리 128MB 사용 시
= 100 × 128MB = 12.8GB (전체 클러스터)
Kubernetes 설정 예시:
spec:
containers:
# 애플리케이션 컨테이너
- name: order-service
env:
- name: OTEL_EXPORTER_OTLP_ENDPOINT
value: "http://localhost:4317" # Sidecar Collector로 전송
# Sidecar Collector
- name: otel-collector
image: otel/opentelemetry-collector:latest
resources:
limits:
memory: 128Mi
2. DaemonSet 패턴
구조: 각 Node마다 Collector Pod 1개만 배포된다. 같은 Node의 모든 Pod이 공유한다.
Node 1
├── Pod: otel-collector (DaemonSet) ← 모든 Pod이 이거 사용
├── Pod: order-service-1
├── Pod: order-service-2
├── Pod: payment-service-1
└── Pod: notification-service-1
Node 2
├── Pod: otel-collector (DaemonSet) ← 모든 Pod이 이거 사용
├── Pod: inventory-service-1
├── Pod: inventory-service-2
└── Pod: shipping-service-1
데이터 흐름:
애플리케이션 → Node IP:4317 (DaemonSet Collector) → Gateway Collector → Backend
장점:
- 리소스 효율성: Node 10개 = Collector 10개 (Pod 수와 무관)
- 중앙 관리: 설정 변경 시 DaemonSet만 업데이트
- 일관성: 모든 Pod이 동일한 Collector 버전/설정 사용
- Node 메트릭 수집: Kubelet, cAdvisor 메트릭 수집 가능
- 로그 파일 접근: Node 파일 시스템에서 직접 로그 수집 가능
단점:
- Node 장애 영향: Node 죽으면 해당 Node의 모든 Pod 데이터 손실
- 네트워크 홉 추가: Pod → Node IP (localhost 아님)
- 설정 공유: 모든 서비스가 동일한 Collector 설정 사용
- 서버리스 불가: AWS Fargate, GCP Cloud Run에서 사용 불가
리소스 사용량 예시:
Node 10개, Collector당 메모리 256MB 사용 시
= 10 × 256MB = 2.56GB (전체 클러스터)
Sidecar 대비 약 80% 절감 (Pod 100개 기준)
Kubernetes 설정 예시:
# DaemonSet 설정 (핵심만 발췌)
kind: DaemonSet
spec:
template:
spec:
hostNetwork: true # Node 네트워크 사용
containers:
- name: otel-collector
ports:
- hostPort: 4317 # Node IP:4317로 접근 가능
resources:
limits:
memory: 256Mi
애플리케이션 환경변수:
env:
- name: NODE_IP
valueFrom:
fieldRef:
fieldPath: status.hostIP # Node IP를 환경변수로
- name: OTEL_EXPORTER_OTLP_ENDPOINT
value: "http://$(NODE_IP):4317" # DaemonSet Collector로 전송
3. 비교 요약
| 구분 | Sidecar | DaemonSet |
|---|---|---|
| 배포 단위 | Pod마다 1개 | Node마다 1개 |
| 리소스 사용 | 높음 (Pod × Collector) | 낮음 (Node × Collector) |
| 네트워크 | localhost (Pod 내부) | Node IP (Pod 간 통신) |
| 격리성 | 높음 (Pod별 독립) | 낮음 (Node 공유) |
| 설정 유연성 | 높음 (팀별 설정 가능) | 낮음 (통일된 설정) |
| 장애 영향 범위 | Pod 단위 | Node 단위 |
| 서버리스 지원 | 가능 (Fargate, Cloud Run) | 불가능 |
| Node 메트릭 | 수집 불가 | 수집 가능 |
| 관리 복잡도 | 높음 | 낮음 |
권장 사항
DaemonSet 사용해야하는 케이스:
- 단일 플랫폼 팀이 운영
- 리소스 효율성이 중요
- Node/Pod 메트릭 수집 필요
- 통일된 관측성 정책 적용
Sidecar 사용해야하는 케이스:
- 팀별 독립적인 Collector 설정 필요
- 높은 격리성이 요구됨 (보안, 멀티테넌시)
- 특정 서비스만 고급 프로세싱 필요
Q4: @Async 메서드에서도 trace_id가 자동으로 전파되나?
OpenTelemetry Java Agent를 쓰면 @Async, ExecutorService, CompletableFuture 등 대부분의 비동기 방식에서 자동으로 Context가 전파된다. MDC의 trace_id도 함께 전달된다.
단, 직접 new Thread()로 스레드를 생성하면 Context가 끊긴다. 이 경우 Context.current().wrap(runnable)로 명시적으로 감싸야 한다.
Q5: Mimir Ingester가 죽으면 버퍼 데이터는 소실되나?
Mimir는 기본적으로 복제 계수(replication factor) 3으로 동작한다. Ingester 3개에 동일한 데이터를 중복 저장하므로, Ingester 하나가 죽어도 데이터가 소실되지 않는다. 나머지 2개에서 데이터를 복구할 수 있다.
단일 노드 모드(monolithic)로 띄우면 복제가 없으므로, 프로덕션에서는 최소 3개 이상의 Ingester를 운영해야 한다.
Q6: TraceQL과 PromQL의 문법 차이는?
기본 철학은 비슷하지만 세부 문법이 다르다.
# PromQL - 메트릭 기반
http_requests_total{status="500"} > 100
# TraceQL - Span 기반
{ status = error && http.status_code = 500 && duration > 1s }
PromQL은 시계열 데이터를 다루고, TraceQL은 Span 속성을 다룬다. PromQL 경험이 있으면 TraceQL도 금방 익힐 수 있다.
마무리
OpenTelemetry와 Grafana Stack을 사용하면 Traces, Metrics, Logs를 하나의 플랫폼에서 통합 관리할 수 있다. 기존에는 Prometheus, Jaeger, ELK를 각각 운영해야 했지만, 이제는 Grafana 하나로 모든 관측성 데이터를 확인할 수 있다.
핵심 개념을 정리하면 다음과 같다.
- OpenTelemetry는 관측성 데이터 수집의 표준이며, OTLP로 통일된 전송 방식을 제공한다
- Tempo는 Object Storage 기반 분산 트레이싱 백엔드로, Jaeger 대비 비용이 저렴하다
- Mimir는 Prometheus의 장기 저장소로, 10억 개 이상의 메트릭을 처리할 수 있다
- Loki는 레이블 기반 로그 시스템으로, Elasticsearch보다 비용이 낮다
- Grafana에서 Trace ID를 기준으로 Metrics, Logs, Traces를 연결할 수 있다
실무에서 도입할 때는 다음 사항을 고려해야 한다.
- 샘플링 설정으로 비용 최적화 (Tail Sampling 활용)
- Cardinality 폭발 방지 (tag 값은 제한된 범위로)
- 민감 정보 필터링 (Authorization 헤더, 개인정보 등)
- 데이터 보관 주기 설정 (Tempo 14일, Mimir 30일 등)
참고문헌
OpenTelemetry 공식 문서
- OpenTelemetry OTLP Specification 1.9.0
- OpenTelemetry Java Instrumentation
- OpenTelemetry Spring Boot Starter
- OpenTelemetry Collector Configuration
Spring 공식 문서
- OpenTelemetry with Spring Boot - Spring Blog
- Spring Boot Actuator - Metrics
- Spring Boot 4 OpenTelemetry Guide - Foojay
