MSA(마이크로서비스 아키텍처) 개념과 패턴
MSA란?
과거 넷플릭스에 근무했던 개발자인 애드리안 콕크로프트(Adrian Cockcroft)는 MSA를 경계 컨텍스트(bounded context)가 있는 느슨하게 결합된 element로 구성된 서비스 지향 아키텍처라고 정의합니다.
확장 큐브라는 애플리케이션을 확장하는 3가지 방법을 정의하는 큐브를 기반으로도 MSA를 살펴볼 수 있습니다.
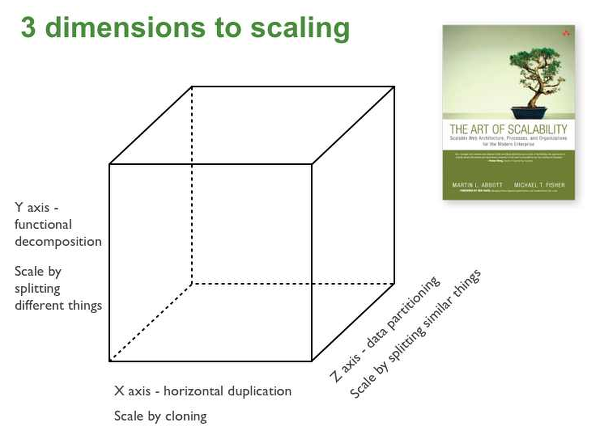 MSA 구조 예시 [1]
MSA 구조 예시 [1]
확장 큐브에서는 애플리케이션을 X축, Y축, Z축 세 방향으로 확장시킬 수 있습니다.
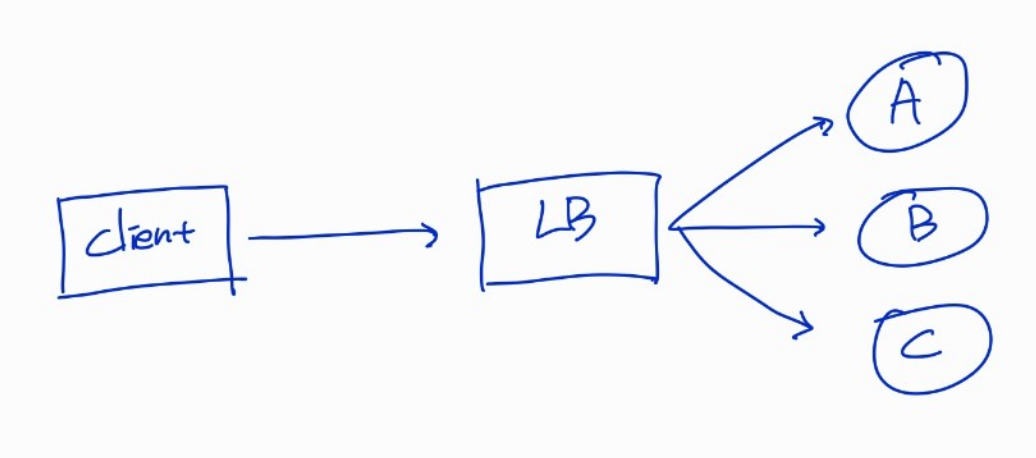
X축 확장은 Load Balancer 뒷단에 인스턴스를 여러 개 띄워놓고, Load Balancer를 통해 요청을 인스턴스에 고루 분배하는 방식입니다.
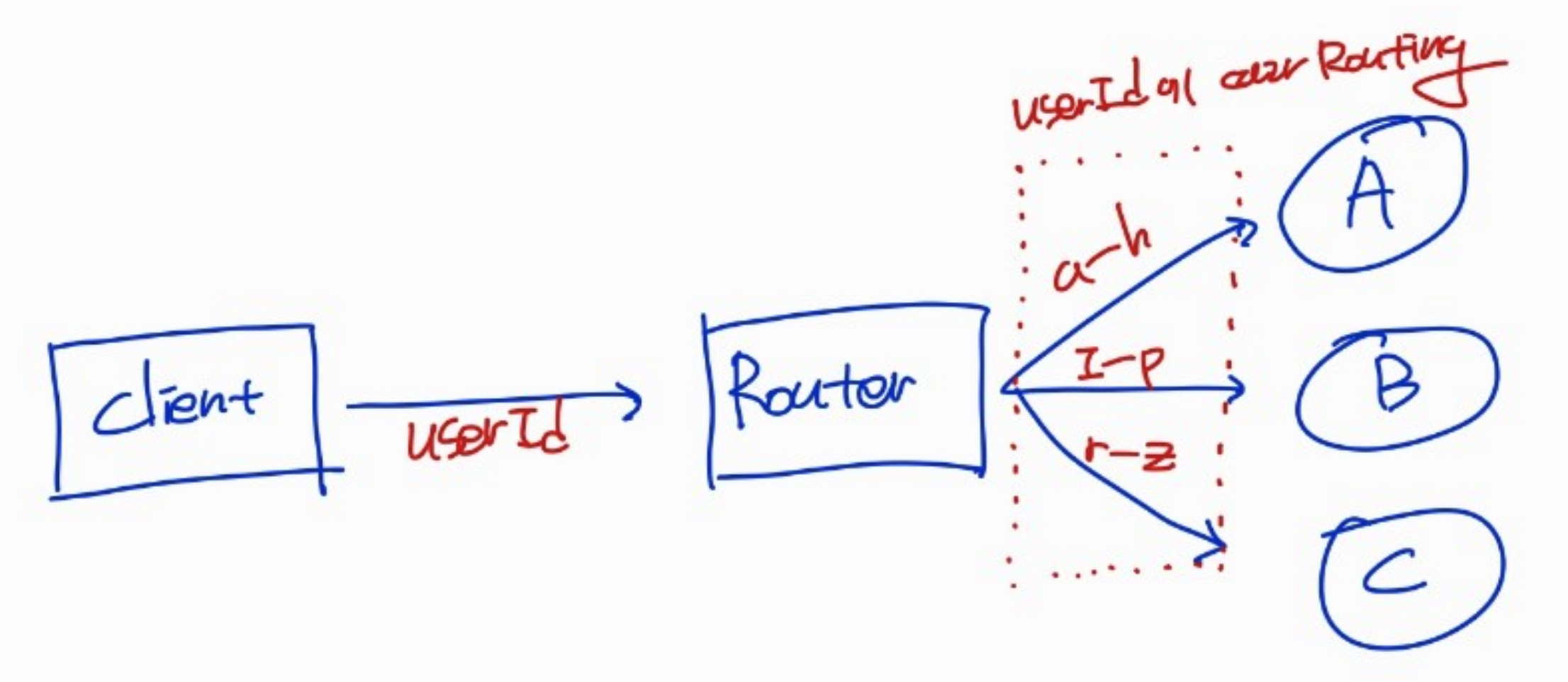
Z축 확장은 요청별로 라우팅 목적지를 다르게 하는 것입니다. 예를 들어 사용자 ID의 해시값에 따라 특정 서버로 라우팅하는 샤딩 방식이 여기에 해당합니다.
Y축 확장은 애플리케이션을 기능적으로 분해하는 것입니다. 이때 기능적으로 쪼개진 각 서비스는 특정 기능을 담당하며 X축/Z축으로 확장될 수 있습니다.
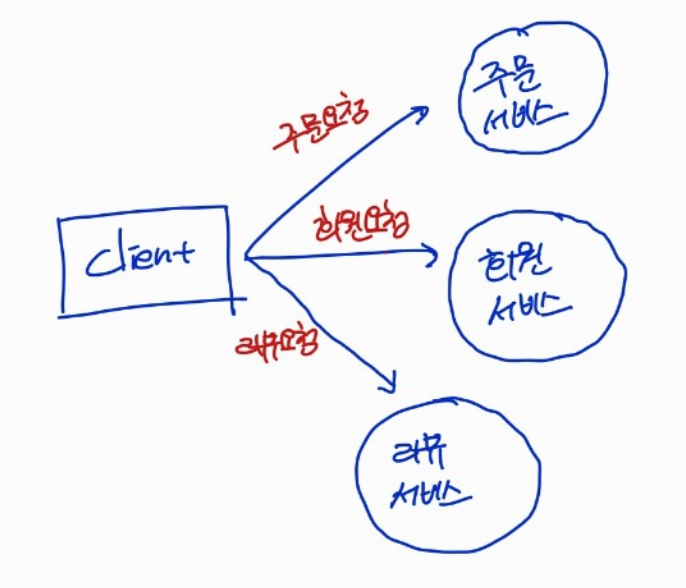
MSA는 확장 큐브에서 Y축 확장과 같이 하나의 애플리케이션을 여러 서비스로 기능 분해하는 아키텍처 스타일입니다. 서비스를 모듈성의 단위로 사용하며, 각 서비스는 다른 서비스가 함부로 규칙을 어기고 침투하지 못하게 API를 통해 통신합니다.
또한 서비스를 빌딩 블록처럼 사용하여 독립적으로 배포/확장할 수 있는 부가적인 장점도 있습니다. 느슨하게 결합된 서비스는 각각 자체 DB를 갖고 있어 다른 서비스가 DB 락을 획득하여 서비스를 blocking 하는 일이 발생하지 않습니다.
모놀리스에서 MSA로 전환을 고려할 때
모든 시스템에 MSA가 적합한 것은 아닙니다. 다음과 같은 상황에서 MSA 전환을 고려해볼 수 있습니다.
전환이 적합한 경우
- 팀 규모가 커져서 하나의 코드베이스에서 협업하기 어려운 경우
- 특정 기능만 빈번하게 배포해야 하는데, 전체 시스템을 재배포해야 하는 경우
- 서비스별로 트래픽 특성이 달라서 개별 확장이 필요한 경우
- 장애 격리가 중요한 경우 (한 기능의 장애가 전체에 영향을 주면 안 되는 경우)
모놀리스가 더 적합한 경우
- 초기 스타트업으로 도메인 경계가 명확하지 않은 경우
- 팀 규모가 작고 빠른 개발이 중요한 경우
- 분산 시스템 운영 경험이 부족한 경우
마틴 파울러는 "Monolith First" 전략을 제안하는데, 처음부터 MSA로 시작하지 말고 모놀리스로 시작하라는 조언입니다. 도메인을 충분히 이해하지 못한 상태에서 서비스를 쪼개면 경계가 잘못 그어지기 쉽고, 나중에 경계를 재조정하는 비용이 매우 큽니다. 도메인 경계가 명확해지면 그때 점진적으로 분리하는 게 더 현실적이죠.
SOA와는 어떻게 다를까?
SOA와 마이크로서비스 모두 시스템을 여러 서비스로 구성하는 아키텍처 스타일인데, 몇 가지 차이점이 존재합니다.
| 구분 | SOA (서비스 지향 아키텍처) | MSA (마이크로서비스 아키텍처) |
|---|---|---|
| 서비스 크기 | 비교적 큼 (비즈니스 기능 단위) | 작음 (하나의 독립적 기능 단위) |
| 서비스 통신 | 주로 SOAP, ESB(Enterprise Service Bus) 기반 | 주로 REST, gRPC, 메시지 브로커(Kafka, RabbitMQ 등) |
| 배포 방식 | 서비스들이 중앙 플랫폼(ESB)에 의존 | 각 서비스가 독립적으로 배포 가능 |
| 데이터 | 전역 데이터 모델 및 통합 DB | 서비스별 개별 데이터 모델 및 독립 DB |
| 도입 시기 | 2000년대 초반 주류 | 2010년대 이후 클라우드 환경에서 급부상 |
| 적합 사례 | 대규모 기업 내부 시스템 통합 | 빠른 배포, 빈번한 업데이트가 필요한 서비스 |
(* SOAP와 REST의 차이점은 AWS 문서에 잘 요약되어 있습니다. SOAP는 프로토콜이고 REST는 아키텍처 스타일입니다.)
MSA의 장단점
장점
-
관리 용이성: 기능 도메인으로 쪼개진 서비스는 모놀리식보다 비교적 규모가 작아서 이해하고 관리하기 쉽습니다.
-
독립적 배포/확장: 서비스를 독립적으로 배포하고 확장할 수 있습니다. 서비스별로 상이한 리소스 요건에 따라 적합한 하드웨어에 배포할 수 있습니다. 예를 들어 CPU intensive한 서비스, Memory intensive한 서비스별로 EC2 instance type을 다르게 지정해서 배포가 가능합니다.
-
장애 격리: 하나의 서비스의 장애가 전체 시스템의 장애로 이어지지 않습니다. Circuit Breaker 패턴을 적용하면 장애 전파를 더 효과적으로 막을 수 있습니다.
-
기술 다양성: 서비스별로 적합한 기술 스택을 선택할 수 있습니다. 예를 들어 실시간 처리가 필요한 서비스는 Node.js로, 복잡한 비즈니스 로직이 필요한 서비스는 Java로 구현할 수 있습니다.
단점
-
분산 모놀리스 위험: 잘못 구축하면 분산 모놀리스(distributed monolith)가 됩니다. 분산 모놀리스란 물리적으로는 서비스가 분리되어 있지만, 서비스 A를 배포할 때 서비스 B도 함께 배포해야 하거나, 서비스 간 동기 호출이 체이닝되어 한 서비스가 느려지면 전체가 느려지는 상황을 말합니다. 모놀리식의 단순함도 없고, MSA의 독립성도 없는 최악의 조합이죠.
-
복잡성 증가
- 서비스 간 통신 실패에 대비한 설계가 필요합니다. (재시도, 타임아웃, 폴백 등)
- DB가 별도로 있기 때문에 데이터 일관성 문제가 존재합니다. (분산 트랜잭션)
- 데이터가 분산되어 있기 때문에 여러 API를 조합하는 경우가 빈번합니다. (API Composition)
- 분산 추적, 중앙 집중식 로깅 등 운영 도구가 필요합니다.
-
네트워크 지연: 서비스 간 호출이 네트워크를 통해 이루어지므로 모놀리스의 in-process 호출보다 느립니다.
MSA 패턴 언어
마이크로서비스 아키텍처 패턴 언어란 MSA를 구성할 때 유용한 패턴의 모음집입니다. MSA를 도입하면 모놀리식 아키텍처에서는 고려하지 않았던 여러 문제가 발생하며, 이를 해결하기 위한 검증된 패턴들입니다.
서비스 디스커버리
MSA 환경에서는 여러 서비스가 IPC(Inter-Process Communication, 프로세스 간 통신)를 통해 유기적으로 호출합니다. HTTP/REST, gRPC, 메시지 큐 등이 대표적인 IPC 방식인데, 어떤 방식을 쓰든 호출하는 클라이언트는 대상 서비스의 네트워크 위치(IP 주소 및 포트)를 알아야 요청을 보낼 수 있습니다. 클라우드 기반의 MSA 애플리케이션은 네트워크 위치가 동적으로 변하기 때문에 이를 특정하기가 까다롭습니다. 이때 등장하는 것이 서비스 디스커버리입니다.
서비스 디스커버리의 핵심 개념은 애플리케이션 인스턴스의 네트워크 위치를 보관하는 서비스 레지스트리입니다. 서비스 인스턴스가 시작/종료될 때마다 이 레지스트리를 동적으로 업데이트합니다.
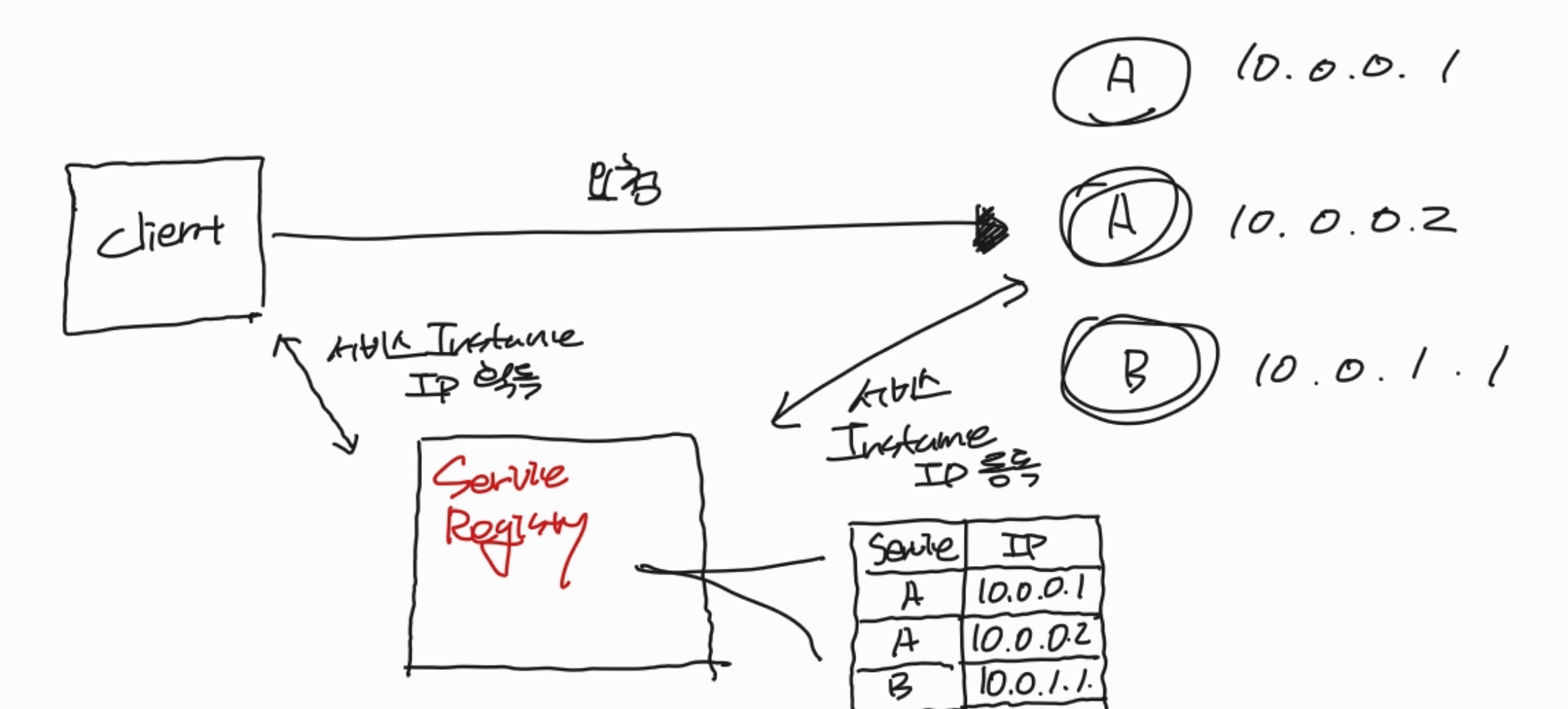
Client-side Discovery: 클라이언트가 서비스 레지스트리에서 인스턴스 목록을 가져와서 직접 로드밸런싱합니다. Netflix Eureka + Spring Cloud LoadBalancer 조합이 대표적입니다. (Netflix Ribbon은 deprecated되어 Spring Cloud LoadBalancer로 대체되었습니다.)
// Spring Cloud에서 @LoadBalanced를 사용한 Client-side Discovery 예시
@Configuration
public class RestTemplateConfig {
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
@Service
public class OrderService {
private final RestTemplate restTemplate;
public OrderService(RestTemplate restTemplate) {
this.restTemplate = restTemplate;
}
public Product getProduct(Long productId) {
// 서비스 이름으로 호출 - Eureka에서 실제 주소를 조회
return restTemplate.getForObject(
"http://product-service/products/" + productId,
Product.class
);
}
}
Server-side Discovery: 로드밸런서가 서비스 레지스트리와 통신하여 라우팅합니다. AWS ALB, Kubernetes Service가 이 방식입니다.
근래에 도입된 배포 플랫폼(쿠버네티스 등)에는 대부분 서비스 레지스트리 메커니즘이 탑재되어 있습니다. [2]
API Gateway
API Gateway는 모든 클라이언트 요청의 단일 진입점 역할을 합니다. 클라이언트가 개별 서비스를 직접 호출하는 대신 API Gateway를 통해 요청하면, Gateway가 적절한 서비스로 라우팅합니다.
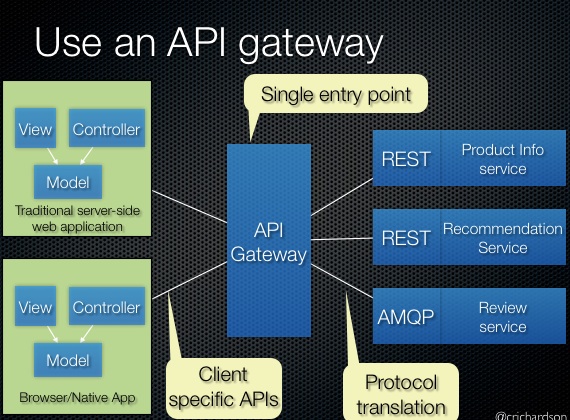 API Gateway 패턴 [5]
API Gateway 패턴 [5]
API Gateway의 주요 기능
- 라우팅: 요청 URL, 헤더 등을 기반으로 적절한 서비스로 라우팅
- 인증/인가: JWT 토큰 검증, API Key 관리 등을 중앙에서 처리
- Rate Limiting: 클라이언트별 요청 제한
- 요청/응답 변환: 프로토콜 변환, 응답 집계(BFF 패턴)
- 로깅/모니터링: 모든 요청에 대한 중앙 집중식 로깅
// Spring Cloud Gateway 라우팅 설정 예시
@Configuration
public class GatewayConfig {
@Bean
public RouteLocator customRouteLocator(RouteLocatorBuilder builder) {
return builder.routes()
.route("user-service", r -> r
.path("/api/users/**")
.filters(f -> f
.stripPrefix(1)
.addRequestHeader("X-Request-Source", "gateway"))
.uri("lb://user-service"))
.route("order-service", r -> r
.path("/api/orders/**")
.filters(f -> f.stripPrefix(1))
.uri("lb://order-service"))
.build();
}
}
대표적인 API Gateway 솔루션으로는 Kong, AWS API Gateway, Spring Cloud Gateway, Netflix Zuul 등이 있습니다.
Circuit Breaker
분산 시스템에서 하나의 서비스 장애가 연쇄적으로 다른 서비스에 전파되는 것을 방지하는 패턴입니다. 전기 회로의 차단기처럼 동작합니다.
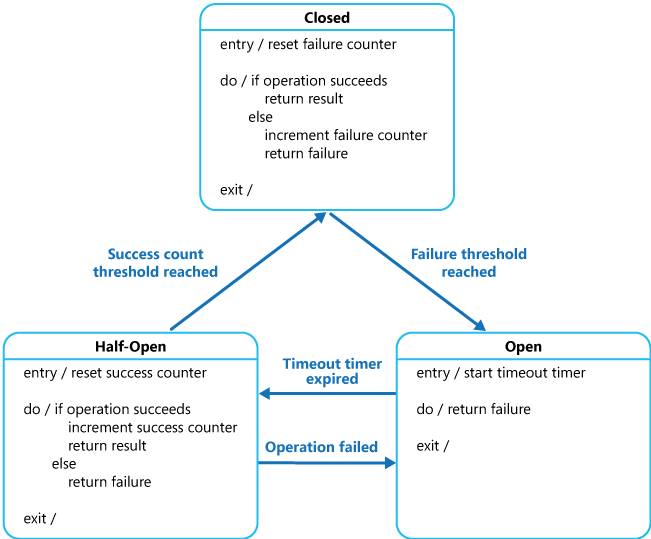 Circuit Breaker 상태 전이 다이어그램 [6]
Circuit Breaker 상태 전이 다이어그램 [6]
상태 전이
- CLOSED: 정상 상태. 모든 요청이 통과합니다.
- OPEN: 장애 감지. 일정 실패율을 초과하면 회로가 열리고, 모든 요청이 즉시 실패 처리됩니다.
- HALF_OPEN: 복구 테스트. 일정 시간 후 일부 요청만 통과시켜 서비스 복구 여부를 확인합니다.
// Resilience4j를 사용한 Circuit Breaker 예시 (Spring Boot 3.x, Resilience4j 2.x)
@Configuration
public class CircuitBreakerConfig {
@Bean
public CircuitBreakerRegistry circuitBreakerRegistry() {
CircuitBreakerConfig config = CircuitBreakerConfig.custom()
.failureRateThreshold(50) // 실패율 50% 이상이면 OPEN
.waitDurationInOpenState(Duration.ofSeconds(30)) // 30초 후 HALF_OPEN
.slidingWindowSize(10) // 최근 10개 요청 기준
.build();
return CircuitBreakerRegistry.of(config);
}
}
@Service
public class OrderService {
private final CircuitBreaker circuitBreaker;
private final ProductClient productClient;
public OrderService(CircuitBreakerRegistry registry, ProductClient productClient) {
this.circuitBreaker = registry.circuitBreaker("productService");
this.productClient = productClient;
}
public Product getProductWithFallback(Long productId) {
// Fallback을 포함한 Supplier 데코레이팅
Supplier<Product> decoratedSupplier = Decorators
.ofSupplier(() -> productClient.getProduct(productId))
.withCircuitBreaker(circuitBreaker)
.withFallback(List.of(CallNotPermittedException.class),
e -> getDefaultProduct(productId))
.decorate();
return decoratedSupplier.get();
}
private Product getDefaultProduct(Long productId) {
// 장애 시 기본값 반환 - 캐시된 데이터나 빈 객체
return new Product(productId, "Unknown", BigDecimal.ZERO);
}
}
Saga 패턴 (분산 트랜잭션)
MSA에서는 각 서비스가 자체 DB를 가지므로 여러 서비스에 걸친 트랜잭션 처리가 어렵습니다. 기존의 2PC(Two-Phase Commit)는 동기 방식이라 성능 저하와 가용성 문제가 있습니다. Saga 패턴은 이를 해결하기 위한 비동기 분산 트랜잭션 패턴입니다.
Saga는 일련의 로컬 트랜잭션으로 구성됩니다. 각 로컬 트랜잭션이 완료되면 다음 트랜잭션을 트리거하고, 실패하면 보상 트랜잭션을 실행합니다.
Choreography 방식: 각 서비스가 이벤트를 발행하고 구독하여 자율적으로 처리합니다.
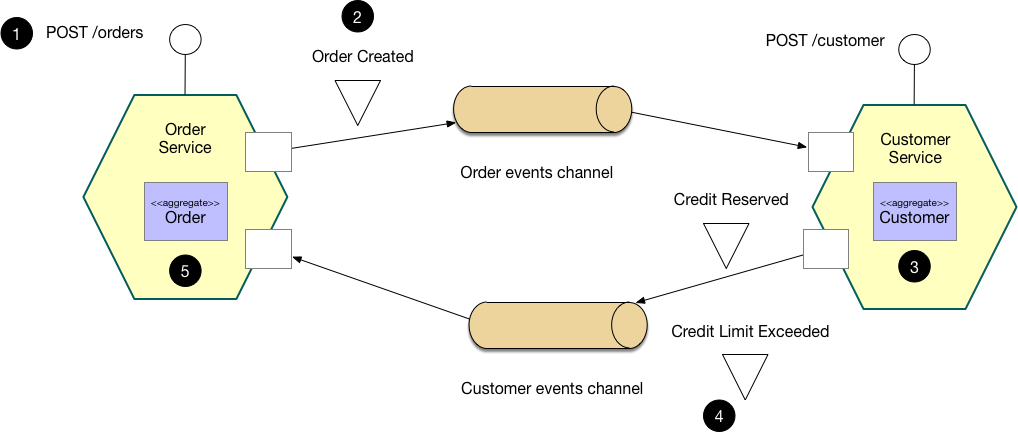 Saga Choreography 방식 [7]
Saga Choreography 방식 [7]
// Choreography 방식 - 이벤트 기반
@Service
public class OrderService {
private final KafkaTemplate<String, OrderEvent> kafkaTemplate;
@Transactional
public Order createOrder(CreateOrderRequest request) {
Order order = orderRepository.save(
new Order(request.getUserId(), request.getItems(), OrderStatus.PENDING)
);
// 이벤트 발행 - Inventory Service가 구독
kafkaTemplate.send("order-events",
new OrderCreatedEvent(order.getId(), order.getItems()));
return order;
}
@KafkaListener(topics = "payment-events")
public void handlePaymentResult(PaymentResultEvent event) {
Order order = orderRepository.findById(event.getOrderId()).orElseThrow();
if (event.isSuccess()) {
order.complete();
} else {
order.cancel();
// 보상 이벤트 발행
kafkaTemplate.send("order-events",
new OrderCancelledEvent(order.getId()));
}
orderRepository.save(order);
}
}
Orchestration 방식: 중앙의 Saga Orchestrator가 전체 흐름을 제어합니다.
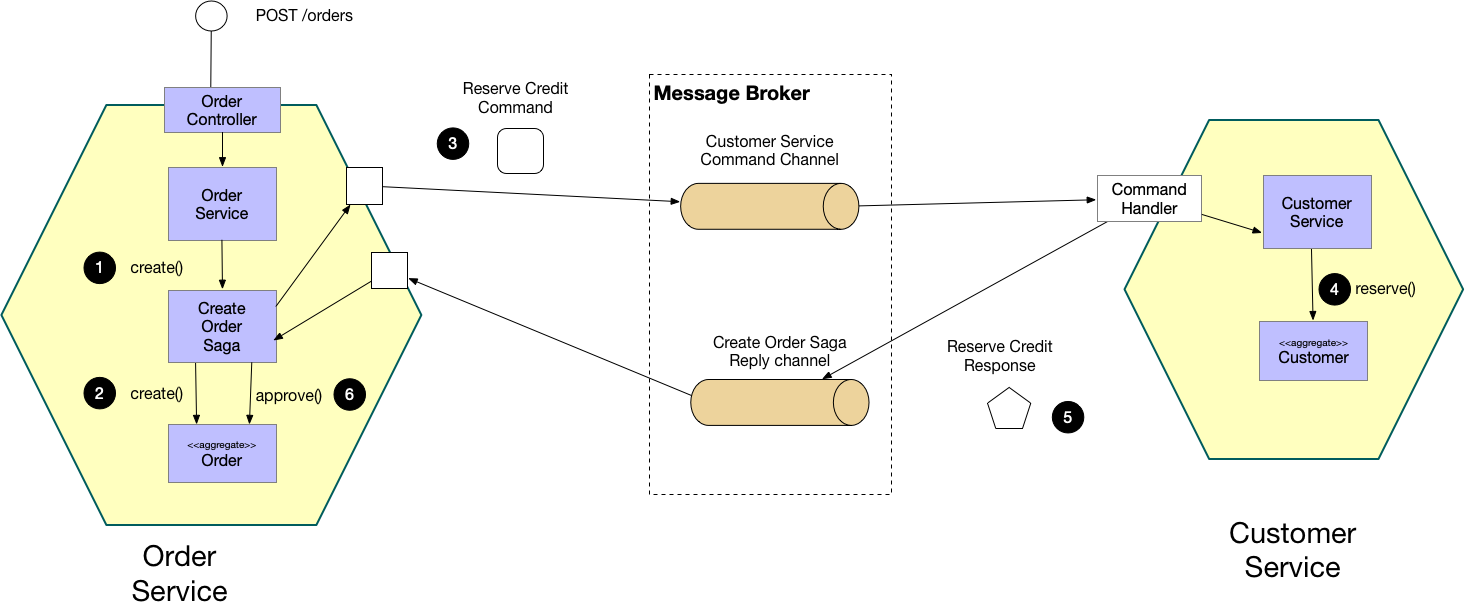 Saga Orchestration 방식 [7]
Saga Orchestration 방식 [7]
// Orchestration 방식 - 중앙 제어
@Service
public class OrderSagaOrchestrator {
private final OrderService orderService;
private final InventoryClient inventoryClient;
private final PaymentClient paymentClient;
public Order processOrder(CreateOrderRequest request) {
Order order = null;
boolean inventoryReserved = false;
try {
// Step 1: 주문 생성
order = orderService.createOrder(request);
// Step 2: 재고 예약
inventoryClient.reserveStock(order.getId(), order.getItems());
inventoryReserved = true;
// Step 3: 결제 처리
paymentClient.processPayment(order.getId(), order.getTotalAmount());
// 모든 단계 성공
order.complete();
return orderService.save(order);
} catch (Exception e) {
// 보상 트랜잭션 실행
if (inventoryReserved) {
inventoryClient.releaseStock(order.getId());
}
if (order != null) {
order.cancel();
orderService.save(order);
}
throw new OrderProcessingException("Order failed", e);
}
}
}
| 구분 | Choreography | Orchestration |
|---|---|---|
| 결합도 | 느슨함 | 상대적으로 높음 |
| 복잡성 | 서비스 수 증가 시 복잡 | 중앙에서 관리 가능 |
| 추적 | 분산되어 추적 어려움 | 중앙에서 추적 용이 |
| 적합 케이스 | 단순한 Saga | 복잡한 비즈니스 로직 |
참고로 보상 트랜잭션도 실패할 수 있습니다. 이 경우 재시도 로직을 구현하거나, Dead Letter Queue에 실패 이벤트를 보관하고 수동으로 처리하는 방법을 사용합니다. 실무에서는 보상 트랜잭션의 멱등성(idempotency)을 보장하는 것이 중요합니다.
이벤트 소싱과 CQRS
MSA에서 데이터 일관성과 조회 성능을 개선하기 위한 패턴입니다.
이벤트 소싱: 상태 변경을 이벤트로 저장합니다. 현재 상태는 이벤트를 순차적으로 재생하여 계산하는데, 이벤트가 많아지면 성능 문제가 생길 수 있습니다. 이를 해결하기 위해 일정 주기로 스냅샷(snapshot)을 저장하고, 스냅샷 이후의 이벤트만 재생하는 방식을 사용합니다.
// 이벤트 소싱 예시
public class Account {
private String id;
private BigDecimal balance = BigDecimal.ZERO;
private List<AccountEvent> events = new ArrayList<>();
public void deposit(BigDecimal amount) {
apply(new MoneyDepositedEvent(id, amount, LocalDateTime.now()));
}
public void withdraw(BigDecimal amount) {
if (balance.compareTo(amount) < 0) {
throw new InsufficientBalanceException();
}
apply(new MoneyWithdrawnEvent(id, amount, LocalDateTime.now()));
}
private void apply(AccountEvent event) {
events.add(event);
if (event instanceof MoneyDepositedEvent e) {
balance = balance.add(e.getAmount());
} else if (event instanceof MoneyWithdrawnEvent e) {
balance = balance.subtract(e.getAmount());
}
}
// 이벤트로부터 상태 복원
public static Account reconstitute(List<AccountEvent> events) {
Account account = new Account();
events.forEach(account::apply);
return account;
}
}
CQRS (Command Query Responsibility Segregation): 명령(쓰기)과 조회(읽기)를 분리합니다. 쓰기에 최적화된 모델과 읽기에 최적화된 모델을 별도로 유지하는데, Write DB에서 발생한 변경 사항은 이벤트(또는 CDC - Change Data Capture)를 통해 Read DB로 비동기 전파됩니다. 이로 인해 최종 일관성(Eventual Consistency)은 보장되지만, 쓰기 직후 조회 시 최신 데이터가 아닐 수 있다는 점을 고려해야 합니다.
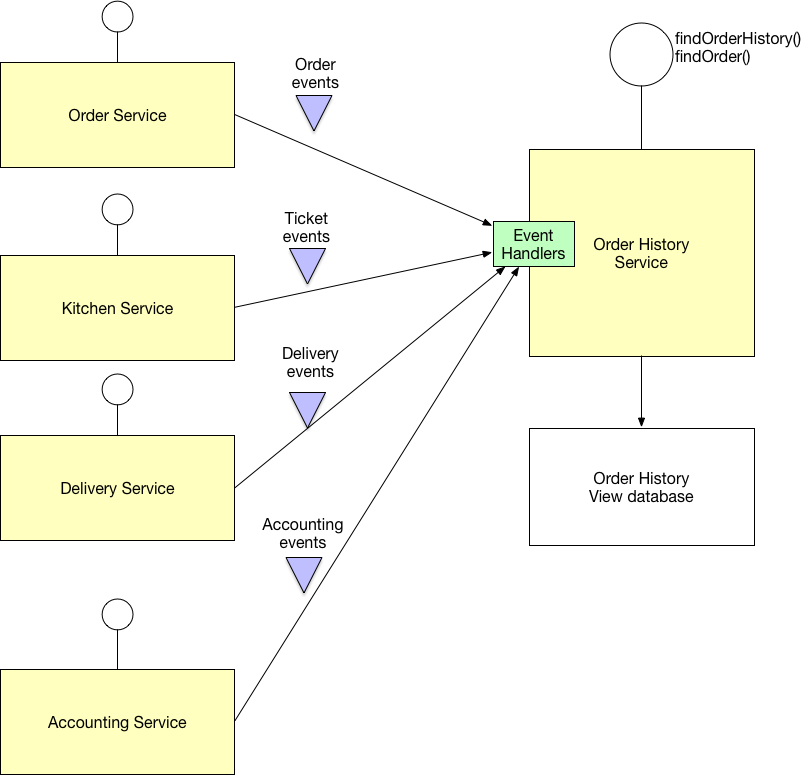 CQRS 패턴 아키텍처 [8]
CQRS 패턴 아키텍처 [8]
마무리
MSA는 복잡한 시스템을 관리 가능한 단위로 분리하고, 독립적인 배포와 확장을 가능하게 하는 아키텍처 스타일입니다. 하지만 "MSA를 하면 좋다"는 말만 듣고 도입하면 분산 모놀리스라는 더 복잡한 상황을 만들 수 있습니다. 팀의 역량, 비즈니스 요구사항, 그리고 운영 환경을 종합적으로 고려해서 결정해야 합니다.
MSA를 성공적으로 도입하려면:
- DDD(Domain-Driven Design)로 도메인 경계를 먼저 명확히 하고, 그 경계를 기준으로 서비스를 분리
- Circuit Breaker, Retry, Timeout 같은 탄력성 패턴을 기본으로 적용
- Zipkin이나 Jaeger 같은 분산 추적, ELK 같은 중앙 집중식 로깅으로 관측성 확보
- CI/CD 파이프라인과 Kubernetes 같은 컨테이너 오케스트레이션으로 배포 자동화
결국 MSA는 기술적 선택이 아니라 조직적 선택에 가깝습니다. 팀 구조와 배포 주기, 확장성 요구사항이 MSA를 필요로 할 때 도입하는 것이 바람직합니다.
참고문헌
- [1] Abbott, Martin L., and Michael T. Fisher. The Art of Scalability: Scalable Web Architecture, Processes, and Organizations for the Modern Enterprise. 2nd ed., Addison-Wesley, 2015. Amazon
- [2] Kubernetes 공식 문서 - 서비스 디스커버리하기
- [3] Chris Richardson. Microservices Patterns. Manning, 2018. microservices.io
- [4] Martin Fowler. MonolithFirst
- [5] Chris Richardson. API Gateway Pattern
- [6] Microsoft Azure Architecture Center. Circuit Breaker Pattern
- [7] Chris Richardson. Saga Pattern
- [8] Chris Richardson. CQRS Pattern
