데이터베이스 인덱스
인덱스가 필요한 이유
1000만 건의 주문 테이블에서 특정 주문을 찾는다고 해보자.
SELECT * FROM orders WHERE order_id = 12345;
인덱스가 없으면? 1000만 건을 처음부터 끝까지 스캔해야 한다. 이걸 Full Table Scan이라고 한다. 1건 찾으려고 1000만 건을 다 읽는 거다. 디스크 I/O 비용이 어마어마하다.
인덱스가 있으면? B+Tree 구조를 타고 3~4번의 탐색으로 원하는 데이터를 찾는다. 1000만 건이든 1억 건이든 탐색 횟수는 거의 비슷하다.
인덱스 없음: O(n) - 데이터가 늘수록 느려짐
인덱스 있음: O(log n) - 데이터가 늘어도 거의 일정
인덱스란
책 뒷편의 색인(찾아보기)을 떠올리면 된다. "트랜잭션"이라는 단어를 찾으려면 책 전체를 읽을 필요 없이, 색인에서 "트랜잭션 - 152p"를 찾고 바로 해당 페이지로 간다.
데이터베이스 인덱스도 마찬가지다. 검색 키(컬럼 값)와 해당 데이터의 물리적 위치(포인터)를 저장한다.
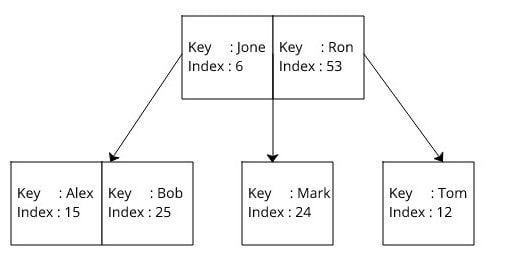 인덱스는 검색 키와 실제 데이터를 가리키는 포인터로 구성된다
인덱스는 검색 키와 실제 데이터를 가리키는 포인터로 구성된다
인덱스의 핵심 특징:
- 원본 데이터와 별도로 저장됨
- 항상 정렬된 상태 유지
- 테이블 하나에 여러 인덱스 생성 가능
- 저장 공간을 추가로 사용
B+Tree 구조
대부분의 RDBMS(MySQL, PostgreSQL, Oracle)는 B+Tree 인덱스를 사용한다.
B+Tree란
B+Tree는 B-Tree를 개선한 자료구조다. 모든 데이터가 리프 노드에만 저장되고, 리프 노드끼리 연결되어 있다.
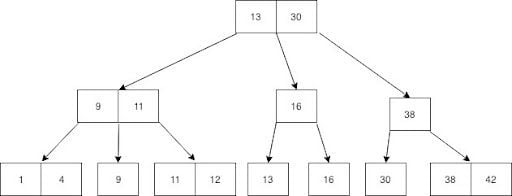 B+Tree 구조 - Root, Branch, Leaf 노드로 구성되며 Leaf 노드가 Linked List로 연결됨
B+Tree 구조 - Root, Branch, Leaf 노드로 구성되며 Leaf 노드가 Linked List로 연결됨
B+Tree 특징
| 구분 | B-Tree | B+Tree |
|---|---|---|
| 데이터 위치 | 모든 노드 | 리프 노드만 |
| 리프 노드 연결 | 없음 | Linked List |
| 범위 검색 | 트리 재탐색 필요 | 순차 탐색 가능 |
| 검색 성능 | 불균일 | 균일 (항상 리프까지) |
B+Tree가 DB에 적합한 이유:
- 범위 검색 효율: 리프 노드가 연결되어 있어서
BETWEEN,>,<쿼리에 유리 - 균일한 성능: 어떤 데이터든 리프까지 동일한 깊이로 탐색
- 높은 팬아웃: 브랜치 노드에 데이터가 없어서 더 많은 키를 저장 가능
탐색 과정
order_id = 35를 찾는 과정:
1. Root 노드 탐색
[50, 80] → 35 < 50 이므로 왼쪽 자식으로
2. Branch 노드 탐색
[20, 35] → 20 ≤ 35 ≤ 35 이므로 가운데 자식으로
3. Leaf 노드 도착
[35, 40] → 35 발견! → 포인터 따라 실제 데이터 접근
트리 높이가 3이면 3번의 I/O로 원하는 데이터를 찾는다. 1000만 건이어도 높이는 보통 3~4 수준이다.
클러스터드 vs 논클러스터드 인덱스
클러스터드 인덱스 (Clustered Index)
테이블 데이터 자체가 인덱스 순서대로 물리적으로 정렬되어 저장된다.
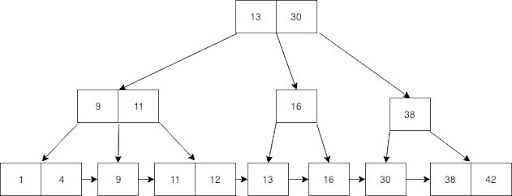 클러스터드 인덱스에서 Leaf 노드는 실제 데이터 row를 포함한다
클러스터드 인덱스에서 Leaf 노드는 실제 데이터 row를 포함한다
특징:
- 테이블당 1개만 존재 (데이터 물리적 정렬은 하나뿐)
- MySQL InnoDB는 PK가 자동으로 클러스터드 인덱스
- 리프 노드에 실제 데이터가 저장됨
- 범위 검색에 매우 유리 (물리적으로 인접)
논클러스터드 인덱스 (Non-Clustered Index)
인덱스와 데이터가 분리되어 저장된다. 인덱스 리프 노드에는 실제 데이터가 아닌 포인터가 있다.
-768.webp) 논클러스터드 인덱스의 Leaf 노드는 PK 값(포인터)을 저장하고, 실제 데이터 접근 시 클러스터드 인덱스를 다시 탐색한다
논클러스터드 인덱스의 Leaf 노드는 PK 값(포인터)을 저장하고, 실제 데이터 접근 시 클러스터드 인덱스를 다시 탐색한다
특징:
- 테이블당 여러 개 생성 가능
- MySQL InnoDB에서는 리프 노드에 PK 값 저장
- 데이터 접근 시 추가 I/O 발생 (클러스터드 인덱스 재탐색)
비교 정리
| 구분 | 클러스터드 인덱스 | 논클러스터드 인덱스 |
|---|---|---|
| 개수 | 테이블당 1개 | 여러 개 가능 |
| 리프 노드 | 실제 데이터 | 포인터 (PK 값) |
| 데이터 정렬 | 물리적 정렬됨 | 정렬 안 됨 |
| 범위 검색 | 빠름 | 상대적으로 느림 |
| INSERT | 느림 (정렬 유지) | 빠름 |
복합 인덱스 (Composite Index)
여러 컬럼을 묶어서 하나의 인덱스로 만드는 것이다.
CREATE INDEX idx_user_status_date ON orders (user_id, status, created_at);
컬럼 순서가 중요하다
복합 인덱스는 왼쪽부터 순서대로 사용된다. 이걸 Leftmost Prefix 규칙이라고 한다.
-- idx_user_status_date (user_id, status, created_at)
-- O 인덱스 사용
WHERE user_id = 1
WHERE user_id = 1 AND status = 'COMPLETED'
WHERE user_id = 1 AND status = 'COMPLETED' AND created_at > '2024-01-01'
-- X 인덱스 사용 불가 (user_id 없음)
WHERE status = 'COMPLETED'
WHERE created_at > '2024-01-01'
WHERE status = 'COMPLETED' AND created_at > '2024-01-01'
컬럼 순서 설계 원칙
- 동등 조건(=) 컬럼을 앞에
- 범위 조건(<, >, BETWEEN) 컬럼을 뒤에
- 카디널리티가 높은 컬럼을 앞에 (선택적일수록 앞)
-- 나쁜 예: 범위 조건이 앞에
CREATE INDEX idx_bad ON orders (created_at, user_id, status);
-- 좋은 예: 동등 조건이 앞에
CREATE INDEX idx_good ON orders (user_id, status, created_at);
왜 그럴까? 범위 조건 이후의 컬럼은 인덱스 탐색에 사용되지 못하고 필터링만 된다.
-- idx_good (user_id, status, created_at) 사용 시
WHERE user_id = 1 -- 인덱스 탐색
AND status = 'COMPLETED' -- 인덱스 탐색
AND created_at > '2024-01-01' -- 인덱스 탐색 (범위)
-- idx_bad (created_at, user_id, status) 사용 시
WHERE created_at > '2024-01-01' -- 인덱스 탐색 (범위)
AND user_id = 1 -- 필터링만 (인덱스 탐색 X)
AND status = 'COMPLETED' -- 필터링만 (인덱스 탐색 X)
커버링 인덱스 (Covering Index)
쿼리에 필요한 모든 컬럼이 인덱스에 포함되어 있으면, 테이블에 접근하지 않고 인덱스만으로 결과를 반환할 수 있다.
-- 인덱스: idx_user_status (user_id, status)
-- 커버링 인덱스 O (user_id, status만 필요)
SELECT user_id, status FROM orders WHERE user_id = 1;
-- 커버링 인덱스 X (name은 인덱스에 없음 → 테이블 접근 필요)
SELECT user_id, status, name FROM orders WHERE user_id = 1;
실행 계획에서 Using index가 표시되면 커버링 인덱스가 적용된 것이다.
EXPLAIN SELECT user_id, status FROM orders WHERE user_id = 1;
-- Extra: Using index ← 테이블 접근 없이 인덱스만 사용
커버링 인덱스는 I/O를 대폭 줄여서 성능이 크게 향상된다. 자주 사용되는 쿼리라면 인덱스에 SELECT 컬럼을 추가하는 것도 고려할 만하다.
인덱스 스캔 방식
실행 계획에서 볼 수 있는 인덱스 접근 방식들이다.
| 타입 | 설명 | 성능 |
|---|---|---|
| const | PK/Unique 인덱스로 1건 조회 | 최고 |
| ref | Non-Unique 인덱스로 동등 조건 | 좋음 |
| range | 범위 조건 (BETWEEN, >, <) | 좋음 |
| index | 인덱스 풀 스캔 | 보통 |
| ALL | 테이블 풀 스캔 | 최악 |
-- const: PK로 1건 조회
EXPLAIN SELECT * FROM users WHERE id = 1;
-- range: 범위 조건
EXPLAIN SELECT * FROM orders WHERE created_at BETWEEN '2024-01-01' AND '2024-12-31';
-- ALL: 인덱스 없는 컬럼 조건
EXPLAIN SELECT * FROM orders WHERE memo LIKE '%긴급%';
인덱스를 사용하지 못하는 경우
인덱스가 있어도 사용되지 않는 경우가 있다.
1. 컬럼 가공
-- X: 컬럼에 함수 적용
WHERE YEAR(created_at) = 2024
-- O: 범위로 변경
WHERE created_at >= '2024-01-01' AND created_at < '2025-01-01'
2. 타입 불일치
-- user_id가 VARCHAR인데 숫자로 비교
-- X: 암묵적 형변환 발생
WHERE user_id = 123
-- O: 타입 일치
WHERE user_id = '123'
3. LIKE 앞부분 와일드카드
-- X: 앞에 % → 인덱스 사용 불가
WHERE name LIKE '%철수'
-- O: 뒤에만 % → 인덱스 사용 가능
WHERE name LIKE '김%'
4. OR 조건
-- X: 각 컬럼에 별도 인덱스 필요, 비효율적
WHERE user_id = 1 OR status = 'PENDING'
-- O: UNION으로 분리
SELECT * FROM orders WHERE user_id = 1
UNION ALL
SELECT * FROM orders WHERE status = 'PENDING' AND user_id != 1
5. 부정 조건
-- X: NOT IN, != 은 인덱스 효율이 낮음
WHERE status != 'DELETED'
WHERE status NOT IN ('DELETED', 'CANCELLED')
-- O: 긍정 조건으로 변경 (가능하다면)
WHERE status IN ('PENDING', 'COMPLETED', 'SHIPPED')
인덱스 설계 원칙
인덱스를 만들어야 할 때
- WHERE 절에 자주 사용되는 컬럼
- JOIN 조건에 사용되는 컬럼 (FK 등)
- ORDER BY에 자주 사용되는 컬럼
- 카디널리티가 높은 컬럼 (값의 종류가 다양)
인덱스를 피해야 할 때
- 데이터가 적은 테이블 (수천 건 이하)
- INSERT/UPDATE/DELETE가 빈번한 테이블
- 카디널리티가 낮은 컬럼 (성별, boolean 등)
- 거의 사용되지 않는 컬럼
인덱스 개수 주의
인덱스가 많으면 INSERT/UPDATE/DELETE 성능이 저하된다. 데이터 변경 시 인덱스도 함께 수정되기 때문이다.
INSERT 1건 실행 시:
- 테이블에 데이터 추가
- 인덱스 A 갱신
- 인덱스 B 갱신
- 인덱스 C 갱신
- ...
읽기 위주 시스템은 인덱스 많아도 괜찮지만, 쓰기 위주 시스템은 최소한으로 유지해야 한다.
실행 계획 분석
MySQL에서 실행 계획을 확인하는 방법이다.
EXPLAIN SELECT * FROM orders WHERE user_id = 1 AND status = 'COMPLETED';
주요 확인 포인트:
| 컬럼 | 확인 사항 |
|---|---|
| type | ALL이면 풀 스캔, ref/range/const면 양호 |
| key | 실제 사용된 인덱스 |
| rows | 예상 스캔 row 수 (적을수록 좋음) |
| Extra | Using index(커버링), Using filesort(정렬), Using temporary(임시테이블) |
-- 나쁜 실행 계획 예시
+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
| 1 | SIMPLE | orders | ALL | NULL | NULL | NULL | NULL | 100000 | Using where |
+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
-- 좋은 실행 계획 예시
+----+-------------+--------+------+---------------+--------------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+--------------+---------+-------+------+-------------+
| 1 | SIMPLE | orders | ref | idx_user | idx_user | 4 | const | 10 | Using index |
+----+-------------+--------+------+---------------+--------------+---------+-------+------+-------------+
자주 묻는 질문
Index Hint로 강제로 인덱스 사용할 수 있나요?
가능하다. 옵티마이저가 잘못된 인덱스를 선택할 때 사용한다.
-- MySQL
SELECT * FROM orders USE INDEX (idx_user) WHERE user_id = 1;
SELECT * FROM orders FORCE INDEX (idx_user) WHERE user_id = 1;
SELECT * FROM orders IGNORE INDEX (idx_status) WHERE user_id = 1;
근데 웬만하면 힌트 안 쓰는 게 좋다. 데이터 분포가 바뀌면 힌트가 오히려 독이 될 수 있어서, 옵티마이저를 믿는 게 낫다.
인덱스 재빌드는 언제 하나요?
대량의 DELETE/UPDATE가 발생하면 인덱스에 빈 공간(fragmentation)이 생긴다. 이러면 인덱스 크기가 커지고 성능이 저하된다.
-- MySQL InnoDB
ALTER TABLE orders ENGINE=InnoDB; -- 테이블 재빌드
OPTIMIZE TABLE orders; -- 또는 이것
주기적으로 할 필요는 없고, 인덱스 크기가 비정상적으로 커졌을 때만 하면 된다.
Hash Index는 언제 쓰나요?
동등 조건(=)에서만 사용 가능하고, 범위 검색은 안 된다.
| 비교 | B+Tree | Hash |
|---|---|---|
| 동등 검색 | O(log n) | O(1) |
| 범위 검색 | 가능 | 불가능 |
| 정렬 | 가능 | 불가능 |
MySQL에서는 Memory 엔진에서만 Hash 인덱스를 쓸 수 있다. InnoDB는 Adaptive Hash Index라고 자동으로 생성해주는 기능이 있다.
안 쓰는 인덱스는 어떻게 찾나요?
MySQL에서는 performance_schema를 확인한다.
SELECT
object_schema,
object_name,
index_name
FROM performance_schema.table_io_waits_summary_by_index_usage
WHERE index_name IS NOT NULL
AND count_star = 0
ORDER BY object_schema, object_name;
안 쓰는 인덱스는 쓰기 성능만 잡아먹으니까 과감히 삭제하는 게 좋다.
온라인으로 인덱스 추가 가능한가요?
MySQL 8.0부터는 대부분의 인덱스 작업이 Online DDL로 가능하다. 테이블 락 없이 인덱스를 추가할 수 있다.
-- ALGORITHM=INPLACE: 테이블 복사 없이 추가
-- LOCK=NONE: 락 없이 (읽기/쓰기 모두 허용)
ALTER TABLE orders ADD INDEX idx_status (status), ALGORITHM=INPLACE, LOCK=NONE;
다만 큰 테이블에서는 시간이 오래 걸리고 디스크 I/O 부하가 있으니 트래픽 적은 시간에 하는 게 안전하다.
정리
인덱스 핵심 정리:
- B+Tree: 대부분의 RDBMS가 사용, 리프 노드가 연결되어 범위 검색에 유리
- 클러스터드 인덱스: 테이블당 1개, 데이터가 물리적으로 정렬됨
- 논클러스터드 인덱스: 여러 개 가능, 포인터로 데이터 참조
- 복합 인덱스: 왼쪽 컬럼부터 순서대로 사용됨 (Leftmost Prefix)
- 커버링 인덱스: 인덱스만으로 쿼리 완료, I/O 최소화
- 인덱스 튜닝: 실행 계획 확인, 컬럼 가공 피하기, 적절한 인덱스 개수 유지
