Spring Batch 완벽 가이드 - Job 구성부터 실전 활용까지
배치 처리가 필요한 이유
실시간 처리가 어려운 작업들이 있다.
- 매일 밤 수백만 건의 정산 처리
- 월말 대량 리포트 생성
- 주기적인 데이터 마이그레이션
- 대용량 파일 처리
이런 작업을 실시간 API로 처리하면 타임아웃도 나고, 서버 부하도 심하다. 그래서 배치 처리가 필요하다.
Spring Batch는 엔터프라이즈급 배치 처리를 위한 프레임워크다. 대용량 데이터 처리, 트랜잭션 관리, 재시작/재처리 기능 등을 제공한다.
Spring Batch 아키텍처
Spring Batch는 3개 계층으로 구성된다.
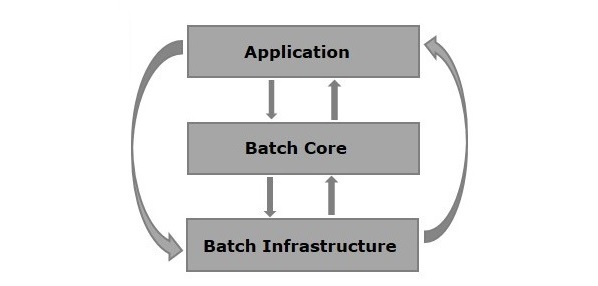
| 계층 | 설명 |
|---|---|
| Application | 개발자가 작성하는 Job, Step, 비즈니스 로직 |
| Batch Core | Job 실행을 위한 핵심 클래스 (JobLauncher, Job, Step) |
| Batch Infrastructure | 공통 Reader, Writer, RetryTemplate 등 |
핵심 구성요소
Spring Batch의 주요 컴포넌트와 흐름을 보자.
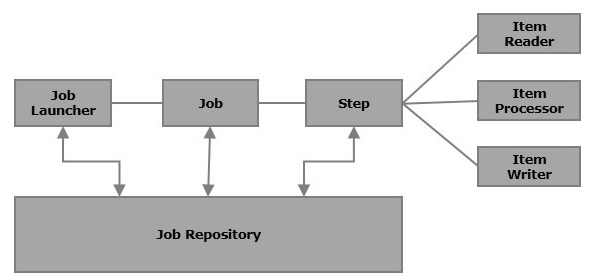
Job
하나의 배치 작업 단위다. 여러 Step으로 구성된다.
Job
├── Step 1 (데이터 추출)
├── Step 2 (데이터 변환)
└── Step 3 (데이터 적재)
Step
Job 내의 독립적인 실행 단위다. 두 가지 방식이 있다.
| 방식 | 설명 | 사용 케이스 |
|---|---|---|
| Tasklet | 단일 작업 수행 | 파일 삭제, 프로시저 호출 |
| Chunk | 데이터를 청크 단위로 처리 | 대용량 데이터 처리 |
Chunk 처리 모델
대부분의 배치 처리는 Chunk 모델을 사용한다.
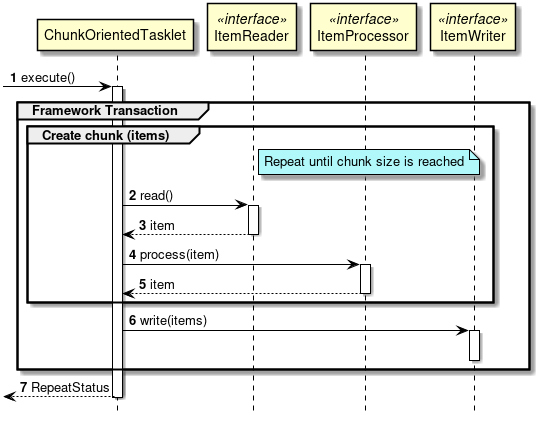
처리 흐름:
- ItemReader: 데이터를 한 건씩 읽음
- ItemProcessor: 읽은 데이터를 가공/변환 (선택)
- ItemWriter: chunk-size만큼 모아서 한번에 쓰기
// chunk-size=100이면
// 100건 읽기 → 100건 처리 → 100건 쓰기 (1 트랜잭션)
// 다음 100건 읽기 → ...
이렇게 하면 메모리 효율도 좋고, 트랜잭션 범위도 적절하게 유지된다.
Job 구현 (Spring Batch 5.x)
Spring Batch 5.0부터 JobBuilderFactory, StepBuilderFactory가 deprecated되었다. 이제 JobBuilder, StepBuilder를 직접 사용한다.
기본 Job 설정
@Configuration
@RequiredArgsConstructor
public class SimpleJobConfig {
private final JobRepository jobRepository;
private final PlatformTransactionManager transactionManager;
@Bean
public Job simpleJob() {
return new JobBuilder("simpleJob", jobRepository)
.start(step1())
.next(step2())
.build();
}
@Bean
public Step step1() {
return new StepBuilder("step1", jobRepository)
.tasklet((contribution, chunkContext) -> {
System.out.println("Step 1 실행");
return RepeatStatus.FINISHED;
}, transactionManager)
.build();
}
@Bean
public Step step2() {
return new StepBuilder("step2", jobRepository)
.tasklet((contribution, chunkContext) -> {
System.out.println("Step 2 실행");
return RepeatStatus.FINISHED;
}, transactionManager)
.build();
}
}
Chunk 기반 Step
대용량 데이터 처리에는 Chunk 방식을 사용한다.
@Bean
public Step chunkStep() {
return new StepBuilder("chunkStep", jobRepository)
.<User, UserDto>chunk(100, transactionManager) // chunk-size: 100
.reader(userReader())
.processor(userProcessor())
.writer(userWriter())
.build();
}
@Bean
public JdbcCursorItemReader<User> userReader() {
return new JdbcCursorItemReaderBuilder<User>()
.name("userReader")
.dataSource(dataSource)
.sql("SELECT id, name, email FROM users WHERE status = 'ACTIVE'")
.rowMapper(new BeanPropertyRowMapper<>(User.class))
.build();
}
@Bean
public ItemProcessor<User, UserDto> userProcessor() {
return user -> {
// 비즈니스 로직: User -> UserDto 변환
return new UserDto(user.getId(), user.getName().toUpperCase());
};
}
@Bean
public JdbcBatchItemWriter<UserDto> userWriter() {
return new JdbcBatchItemWriterBuilder<UserDto>()
.dataSource(dataSource)
.sql("INSERT INTO user_backup (id, name) VALUES (:id, :name)")
.beanMapped()
.build();
}
Job, JobInstance, JobExecution 관계
이 세 가지 개념이 헷갈리기 쉬운데, 명확히 구분해야 한다.
Job
배치 작업의 정의다. "매일 정산 처리"라는 작업을 정의한 것.
JobInstance
Job + JobParameters의 조합이다. 논리적 실행 단위.
Job: DailySettlementJob
└── JobInstance: DailySettlementJob + {date=2024-01-15}
└── JobInstance: DailySettlementJob + {date=2024-01-16}
└── JobInstance: DailySettlementJob + {date=2024-01-17}
같은 Job이라도 파라미터가 다르면 다른 JobInstance다.
JobExecution
JobInstance의 실제 실행. 한 번 실패하고 재시도하면 JobExecution이 2개 생긴다.
JobInstance: DailySettlementJob + {date=2024-01-15}
└── JobExecution #1: FAILED (오류 발생)
└── JobExecution #2: COMPLETED (재시도 성공)
핵심 공식
JobInstance = Job + identifying JobParameters
같은 Job + 같은 JobParameters = 같은 JobInstance
이미 COMPLETED된 JobInstance를 다시 실행하면?
JobInstanceAlreadyCompleteException: A job instance already exists
and is complete for parameters={date=2024-01-15}.
동일한 파라미터로 다시 돌리려면 파라미터를 바꾸거나, FAILED 상태여야 한다.
JobParameter
Job 실행 시 전달되는 파라미터다.
파라미터 전달 방법
1. 커맨드라인에서 전달
java -jar batch.jar date=2024-01-15 type=daily
2. 코드에서 생성
JobParameters params = new JobParametersBuilder()
.addString("date", "2024-01-15")
.addString("type", "daily")
.addLong("timestamp", System.currentTimeMillis()) // 매번 다른 값으로 중복 방지
.toJobParameters();
jobLauncher.run(job, params);
파라미터 사용
@Bean
public Step step1() {
return new StepBuilder("step1", jobRepository)
.tasklet((contribution, chunkContext) -> {
// 방법 1: StepContribution에서
JobParameters params = contribution.getStepExecution()
.getJobExecution()
.getJobParameters();
String date = params.getString("date");
// 방법 2: ChunkContext에서 (Map 형태)
Map<String, Object> paramMap = chunkContext.getStepContext()
.getJobParameters();
return RepeatStatus.FINISHED;
}, transactionManager)
.build();
}
@Value로 주입 (Late Binding)
@Bean
@StepScope // 필수! Step 실행 시점에 빈 생성
public Tasklet myTasklet(@Value("#{jobParameters['date']}") String date) {
return (contribution, chunkContext) -> {
System.out.println("처리 날짜: " + date);
return RepeatStatus.FINISHED;
};
}
@StepScope를 붙여야 Job 실행 시점에 파라미터가 주입된다.
JobLauncher
Job을 실행하는 역할이다.
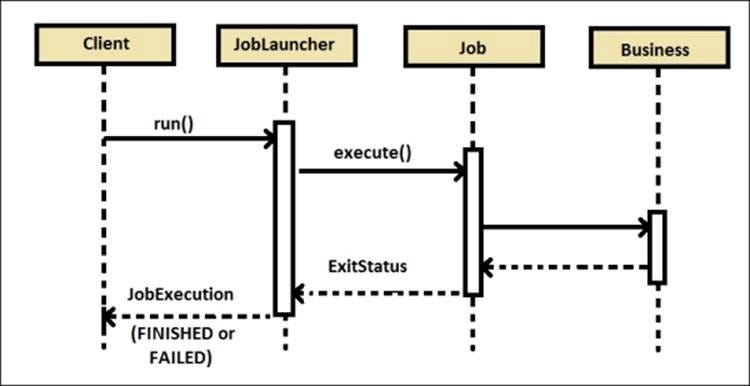
동기 실행 (기본)
@Component
@RequiredArgsConstructor
public class JobRunner implements ApplicationRunner {
private final JobLauncher jobLauncher;
private final Job myJob;
@Override
public void run(ApplicationArguments args) throws Exception {
JobParameters params = new JobParametersBuilder()
.addLong("time", System.currentTimeMillis())
.toJobParameters();
// 동기 실행: Job이 끝날 때까지 대기
JobExecution execution = jobLauncher.run(myJob, params);
System.out.println("Job 상태: " + execution.getStatus());
}
}
비동기 실행
@Configuration
public class AsyncJobConfig {
@Bean
public JobLauncher asyncJobLauncher(JobRepository jobRepository) {
TaskExecutorJobLauncher launcher = new TaskExecutorJobLauncher();
launcher.setJobRepository(jobRepository);
launcher.setTaskExecutor(new SimpleAsyncTaskExecutor());
return launcher;
}
}
비동기로 실행하면 jobLauncher.run()이 바로 리턴된다. 웹 요청으로 배치를 트리거할 때 유용하다.
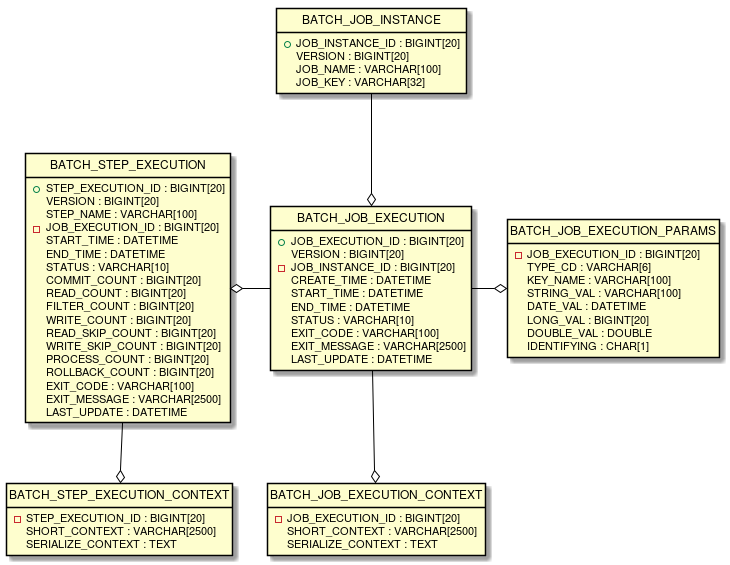
메타 테이블
Spring Batch는 실행 이력을 DB에 저장한다. 6개의 메타 테이블이 있다.
| 테이블 | 설명 |
|---|---|
| BATCH_JOB_INSTANCE | JobInstance 정보 |
| BATCH_JOB_EXECUTION | JobExecution 정보 (상태, 시작/종료 시간) |
| BATCH_JOB_EXECUTION_PARAMS | JobParameter 정보 |
| BATCH_STEP_EXECUTION | StepExecution 정보 |
| BATCH_JOB_EXECUTION_CONTEXT | Job 레벨 ExecutionContext |
| BATCH_STEP_EXECUTION_CONTEXT | Step 레벨 ExecutionContext |
테이블 생성
Spring Boot에서는 자동 생성 설정이 가능하다.
spring:
batch:
jdbc:
initialize-schema: always # always, embedded, never
always: 항상 스키마 생성embedded: 내장 DB(H2)일 때만 생성never: 생성 안 함 (직접 관리)
운영 환경에서는 never로 설정하고 DDL을 직접 실행하는 게 안전하다.
메타 테이블 확인
-- Job 실행 이력
SELECT * FROM BATCH_JOB_EXECUTION ORDER BY JOB_EXECUTION_ID DESC;
-- 실패한 Job 찾기
SELECT * FROM BATCH_JOB_EXECUTION WHERE STATUS = 'FAILED';
-- 특정 Job의 파라미터 확인
SELECT * FROM BATCH_JOB_EXECUTION_PARAMS
WHERE JOB_EXECUTION_ID = 123;
Flow Job - 조건부 실행
Step 실행 결과에 따라 다음 Step을 분기할 수 있다.
@Bean
public Job flowJob() {
return new JobBuilder("flowJob", jobRepository)
.start(step1())
.on("COMPLETED").to(step2()) // step1 성공 → step2
.on("FAILED").to(errorStep()) // step1 실패 → errorStep
.on("*").stop() // 그 외 → 종료
.from(step2())
.on("*").to(step3()) // step2 완료 후 → step3
.end()
.build();
}
커스텀 ExitStatus로 더 세밀한 분기도 가능하다.
@Bean
public Step step1() {
return new StepBuilder("step1", jobRepository)
.tasklet((contribution, chunkContext) -> {
// 비즈니스 로직
if (someCondition) {
contribution.setExitStatus(new ExitStatus("SKIP"));
}
return RepeatStatus.FINISHED;
}, transactionManager)
.build();
}
실전 예제: CSV → DB 적재
실무에서 많이 사용하는 패턴이다.
@Configuration
@RequiredArgsConstructor
public class CsvImportJobConfig {
private final JobRepository jobRepository;
private final PlatformTransactionManager transactionManager;
private final DataSource dataSource;
@Bean
public Job csvImportJob() {
return new JobBuilder("csvImportJob", jobRepository)
.start(csvImportStep())
.build();
}
@Bean
public Step csvImportStep() {
return new StepBuilder("csvImportStep", jobRepository)
.<UserCsv, User>chunk(1000, transactionManager)
.reader(csvReader())
.processor(csvProcessor())
.writer(dbWriter())
.faultTolerant()
.skipLimit(10) // 최대 10건 스킵
.skip(FlatFileParseException.class) // 파싱 에러는 스킵
.build();
}
@Bean
@StepScope
public FlatFileItemReader<UserCsv> csvReader() {
return new FlatFileItemReaderBuilder<UserCsv>()
.name("csvReader")
.resource(new ClassPathResource("users.csv"))
.delimited()
.names("name", "email", "age")
.targetType(UserCsv.class)
.linesToSkip(1) // 헤더 스킵
.build();
}
@Bean
public ItemProcessor<UserCsv, User> csvProcessor() {
return csv -> User.builder()
.name(csv.getName().trim())
.email(csv.getEmail().toLowerCase())
.age(csv.getAge())
.createdAt(LocalDateTime.now())
.build();
}
@Bean
public JdbcBatchItemWriter<User> dbWriter() {
return new JdbcBatchItemWriterBuilder<User>()
.dataSource(dataSource)
.sql("INSERT INTO users (name, email, age, created_at) " +
"VALUES (:name, :email, :age, :createdAt)")
.beanMapped()
.build();
}
}
자주 묻는 질문
Job이 실패했을 때 어디서부터 재시작되나요?
기본적으로 실패한 Step부터 재시작된다. Spring Batch는 각 Step의 진행 상황을 BATCH_STEP_EXECUTION에 저장한다.
Chunk 기반 Step이라면 마지막으로 커밋된 chunk 다음부터 재시작된다.
같은 Job을 동시에 여러 번 실행할 수 있나요?
같은 JobParameters로는 안 된다. 다른 JobParameters를 사용하면 가능.
// timestamp 추가로 매번 다른 JobInstance 생성
JobParameters params = new JobParametersBuilder()
.addString("date", "2024-01-15")
.addLong("run.id", System.currentTimeMillis()) // 구분용
.toJobParameters();
chunk-size는 어떻게 정하나요?
정답은 없지만, 보통 100~1000 사이에서 시작한다.
- 너무 작으면: 커밋이 자주 발생해서 느림
- 너무 크면: 메모리 사용량 증가, 실패 시 재처리 범위 커짐
실제 데이터로 테스트하면서 조정하는 게 좋다.
Reader에서 읽은 데이터를 Step 간에 공유하려면?
ExecutionContext를 사용한다.
// Step 1에서 저장
chunkContext.getStepContext()
.getStepExecution()
.getJobExecution()
.getExecutionContext()
.put("totalCount", count);
// Step 2에서 읽기
Integer totalCount = (Integer) chunkContext.getStepContext()
.getStepExecution()
.getJobExecution()
.getExecutionContext()
.get("totalCount");
스케줄링은 어떻게 하나요?
Spring Batch 자체는 스케줄링 기능이 없다. 별도 스케줄러와 연동해야 한다.
1. @Scheduled 사용 (간단)
@Component
@RequiredArgsConstructor
public class BatchScheduler {
private final JobLauncher jobLauncher;
private final Job dailyJob;
@Scheduled(cron = "0 0 2 * * *") // 매일 새벽 2시
public void runDailyJob() throws Exception {
JobParameters params = new JobParametersBuilder()
.addLong("time", System.currentTimeMillis())
.toJobParameters();
jobLauncher.run(dailyJob, params);
}
}
2. Jenkins, Airflow 같은 외부 스케줄러에서 REST API로 트리거하는 방식도 많이 쓴다.
Cursor Reader vs Paging Reader 차이는?
| 구분 | JdbcCursorItemReader | JdbcPagingItemReader |
|---|---|---|
| 동작 | DB 커서로 한 건씩 스트리밍 | 페이지 단위로 조회 |
| 커넥션 | 전체 처리 동안 유지 | 페이지마다 새 커넥션 |
| 메모리 | 낮음 | 페이지 크기만큼 |
| 재시작 | 어려움 | 쉬움 (페이지 번호 저장) |
| 추천 | 단순/빠른 처리 | 대용량/재시작 필요 시 |
실무에서는 재시작이 중요하므로 PagingItemReader를 더 많이 쓴다.
정리
Spring Batch 핵심 개념:
- Job: 배치 작업 정의, 여러 Step으로 구성
- Step: 실제 작업 단위 (Tasklet 또는 Chunk)
- Chunk: Reader → Processor → Writer, 청크 단위 트랜잭션
- JobInstance: Job + JobParameters, 논리적 실행 단위
- JobExecution: JobInstance의 실제 실행, 실패하면 여러 개 가능
- JobLauncher: Job 실행 담당
- JobRepository: 메타데이터 저장/관리
